# A tibble: 2 × 2
term estimate
<chr> <dbl>
1 (Intercept) 2.56
2 log_inc 0.718Lecture 21
June 16, 2025
# A tibble: 2 × 2
term estimate
<chr> <dbl>
1 (Intercept) 2.56
2 log_inc 0.718
# A tibble: 2 × 2
term estimate
<chr> <dbl>
1 (Intercept) -0.250
2 log_inc 0.964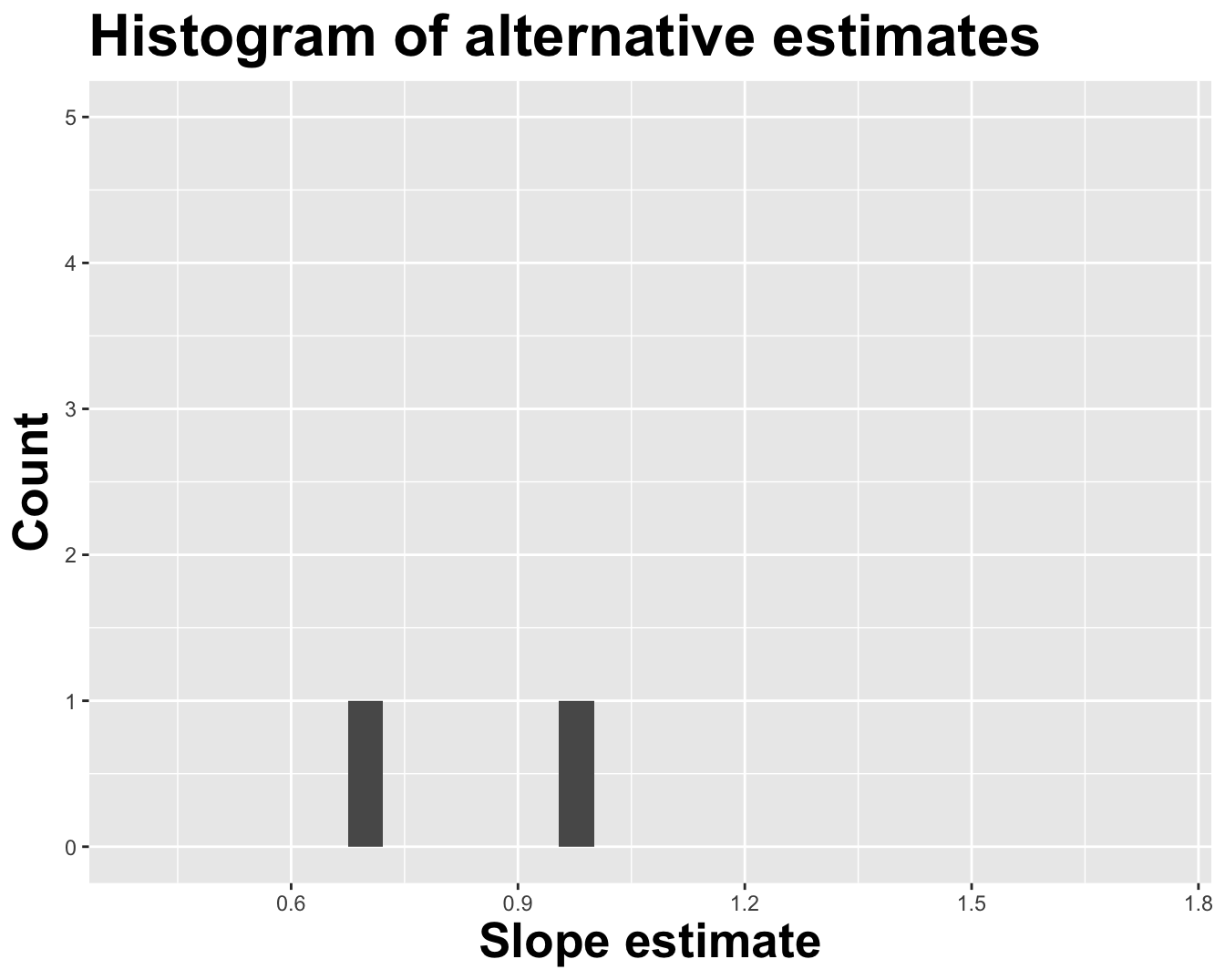
# A tibble: 2 × 2
term estimate
<chr> <dbl>
1 (Intercept) 0.468
2 log_inc 0.885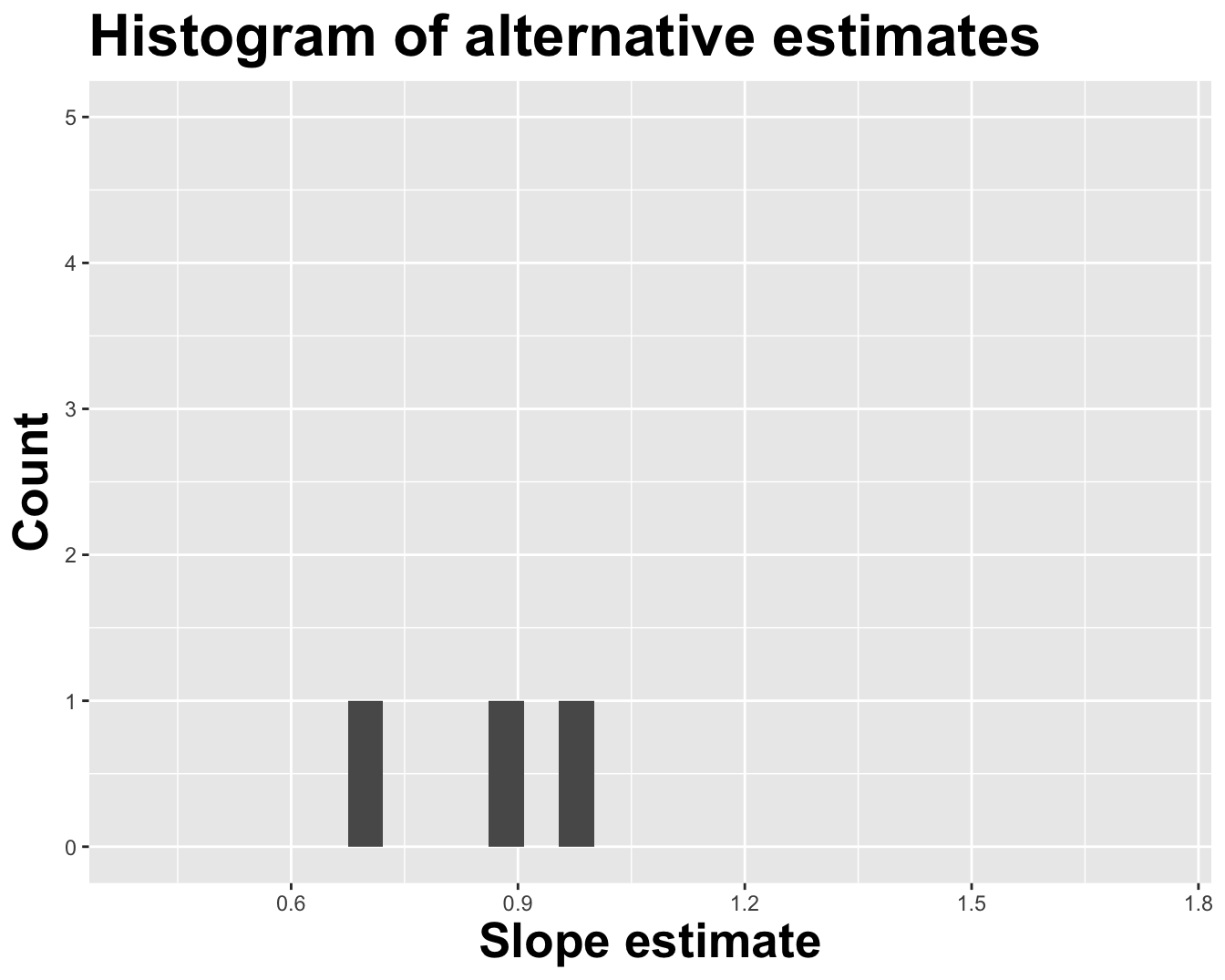
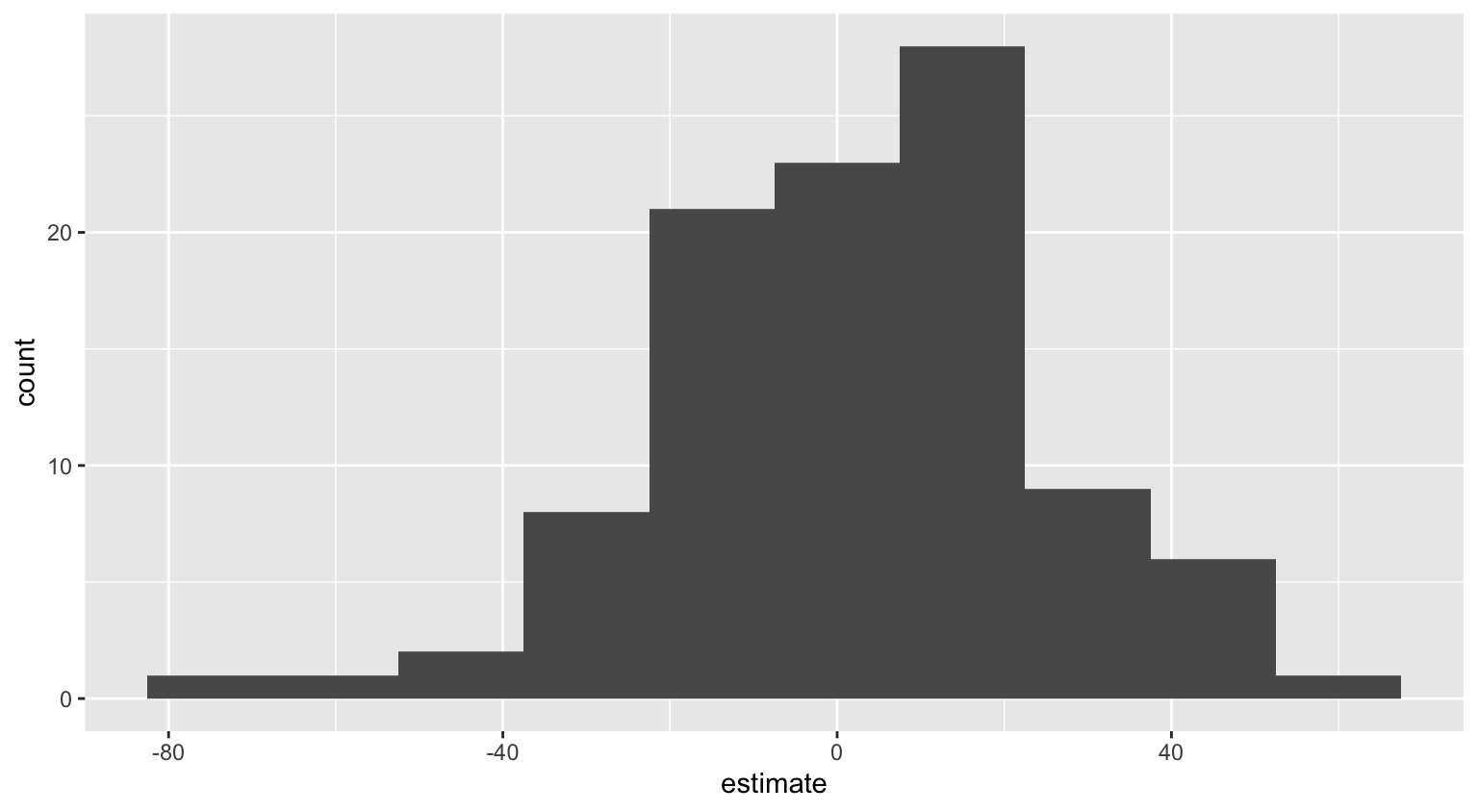
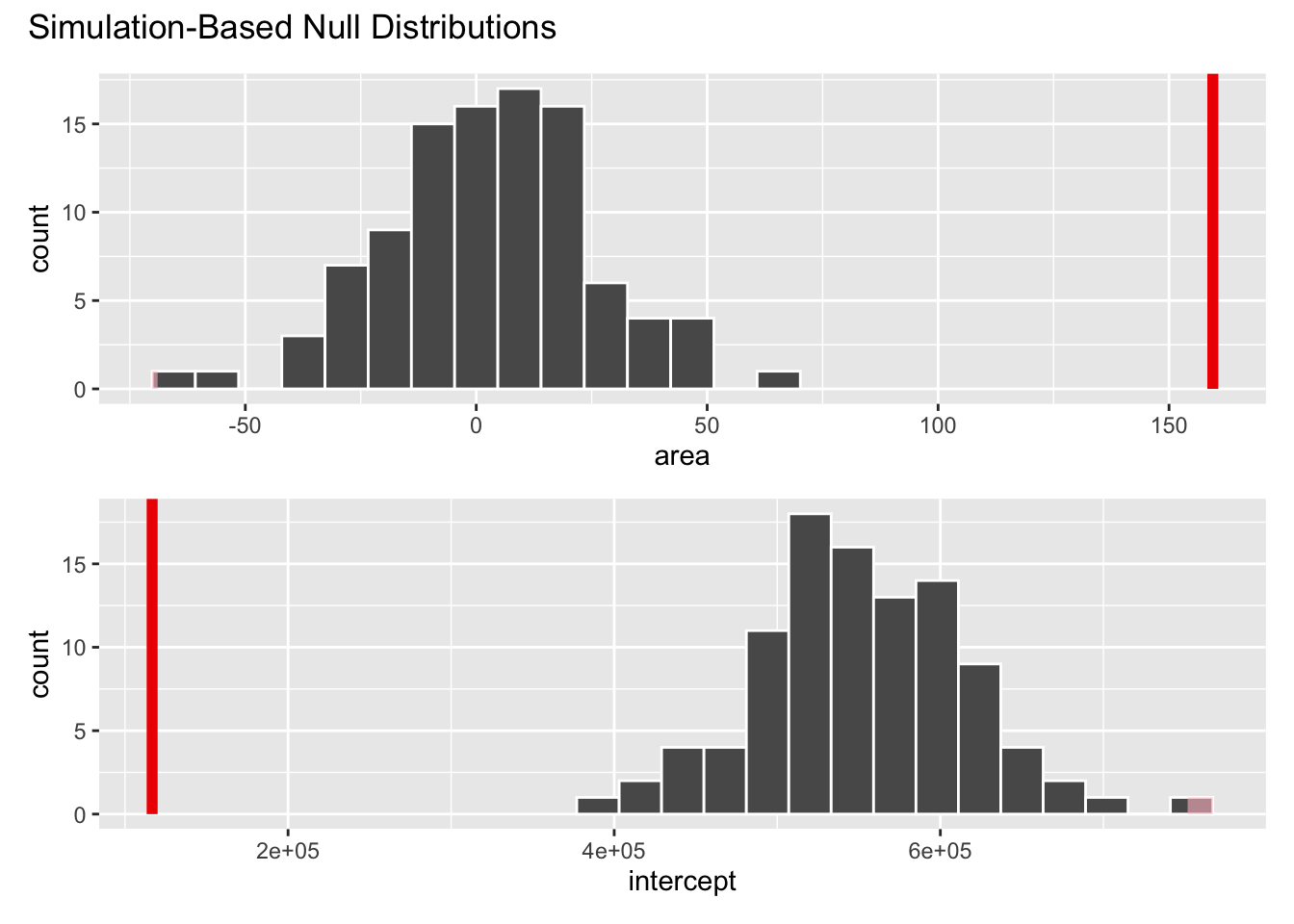
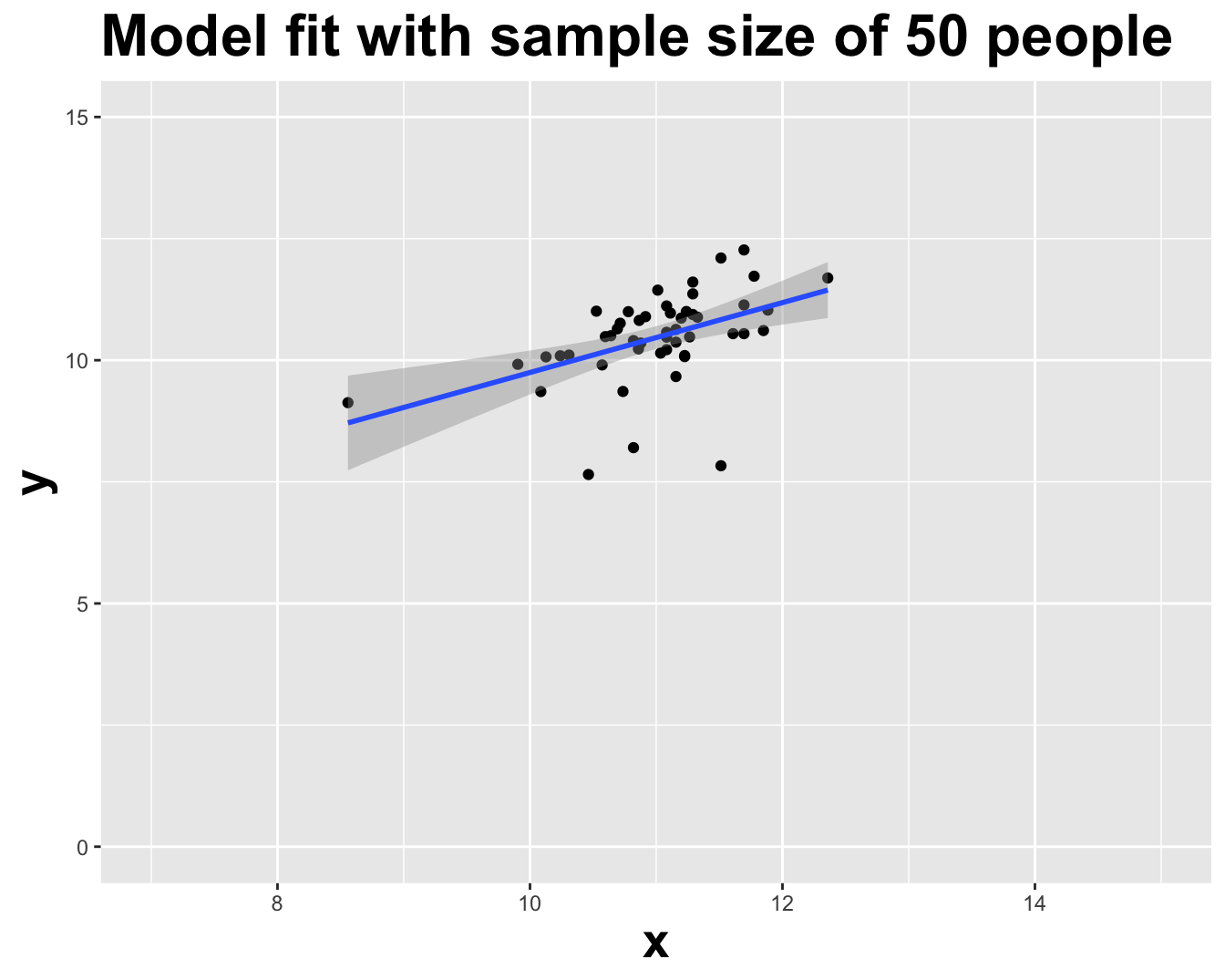
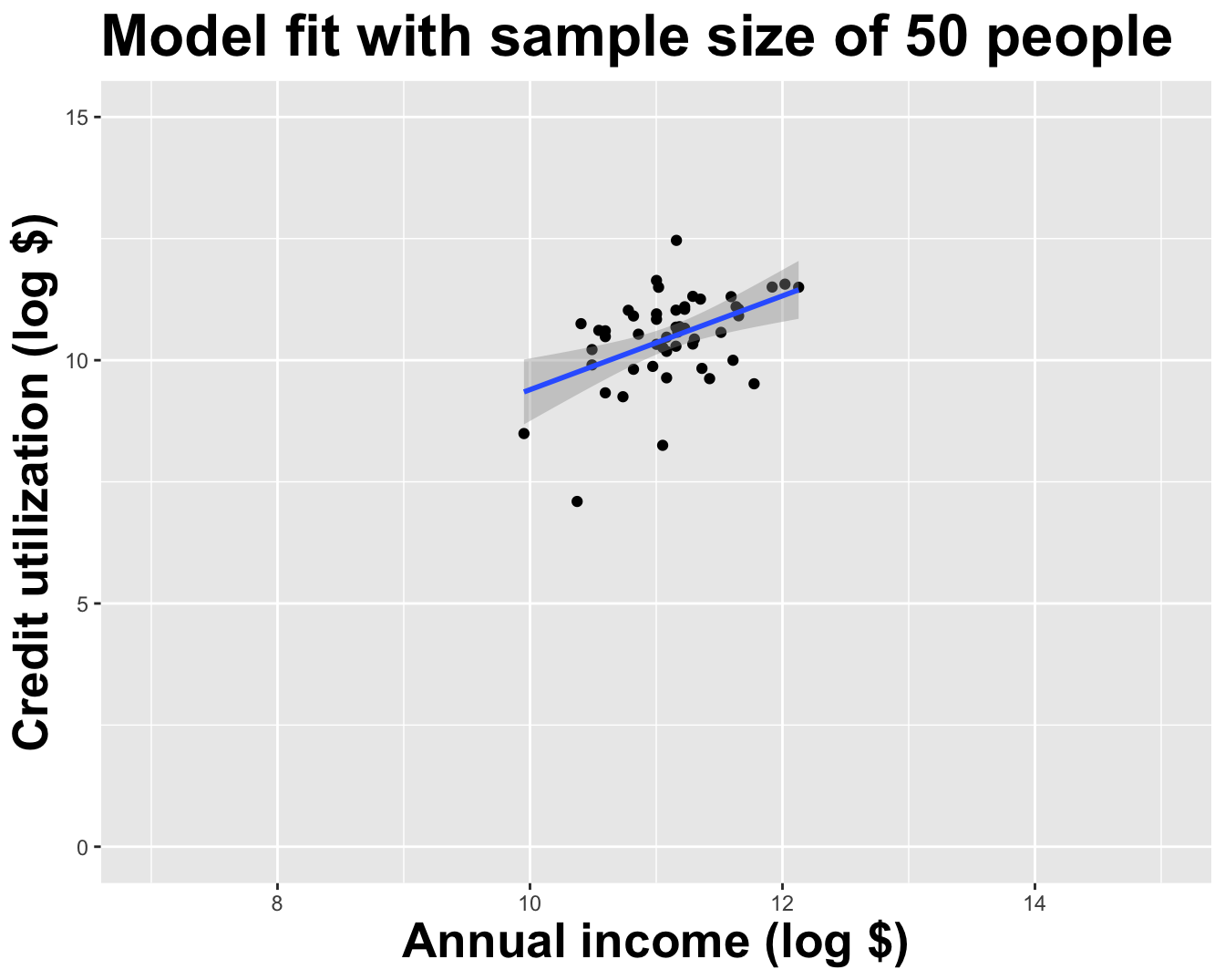
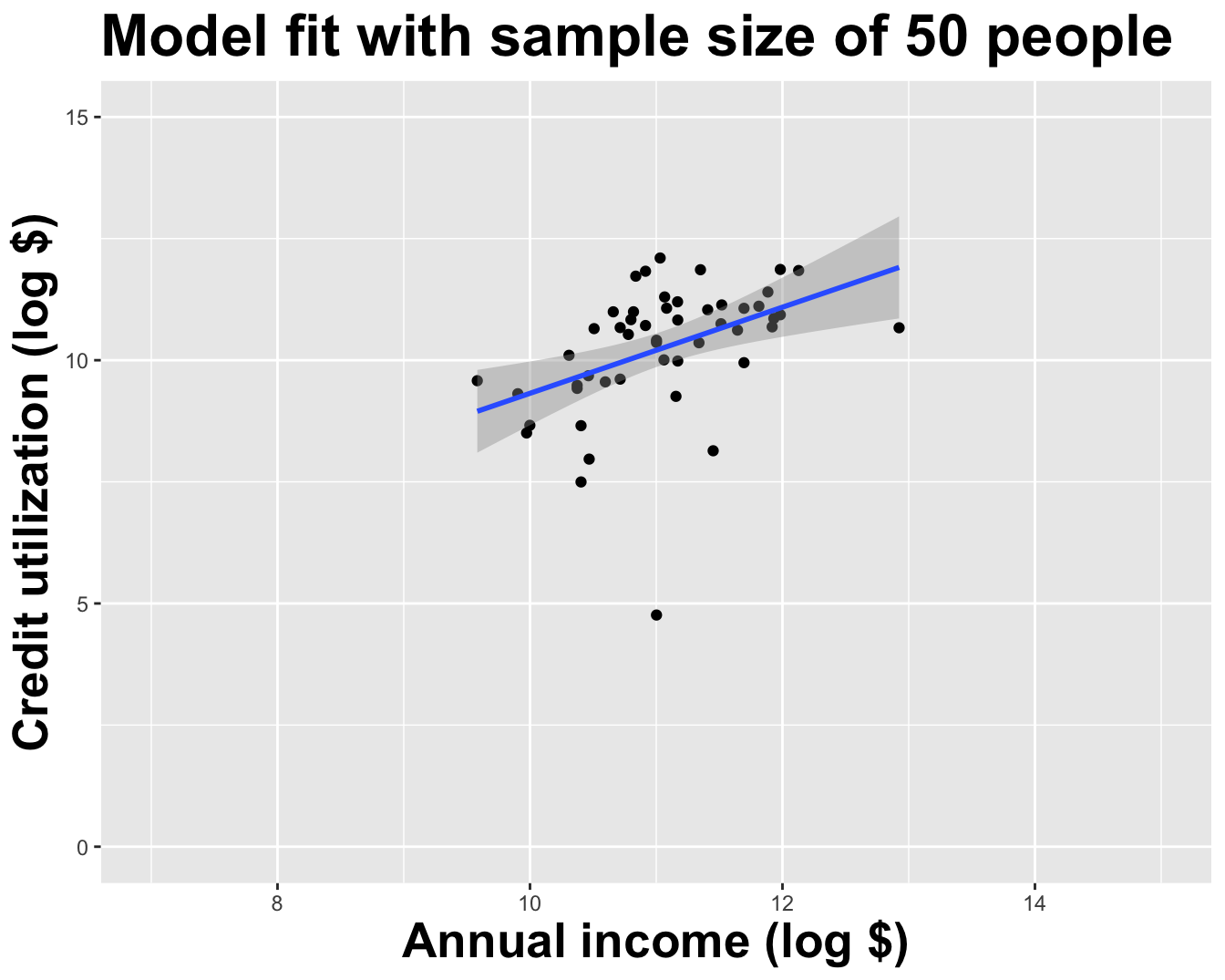
How sensitive are the estimates to the data they are based on?
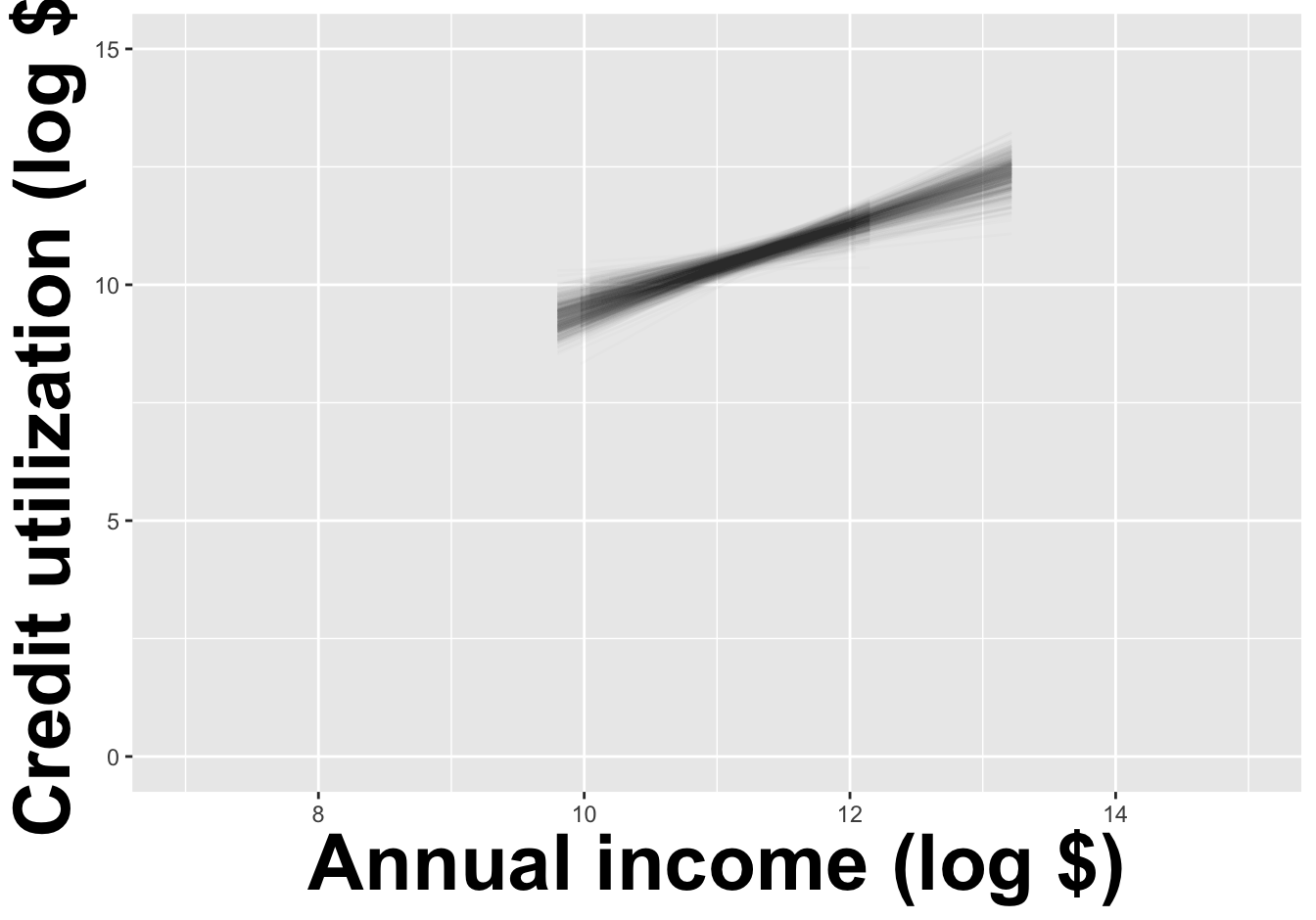
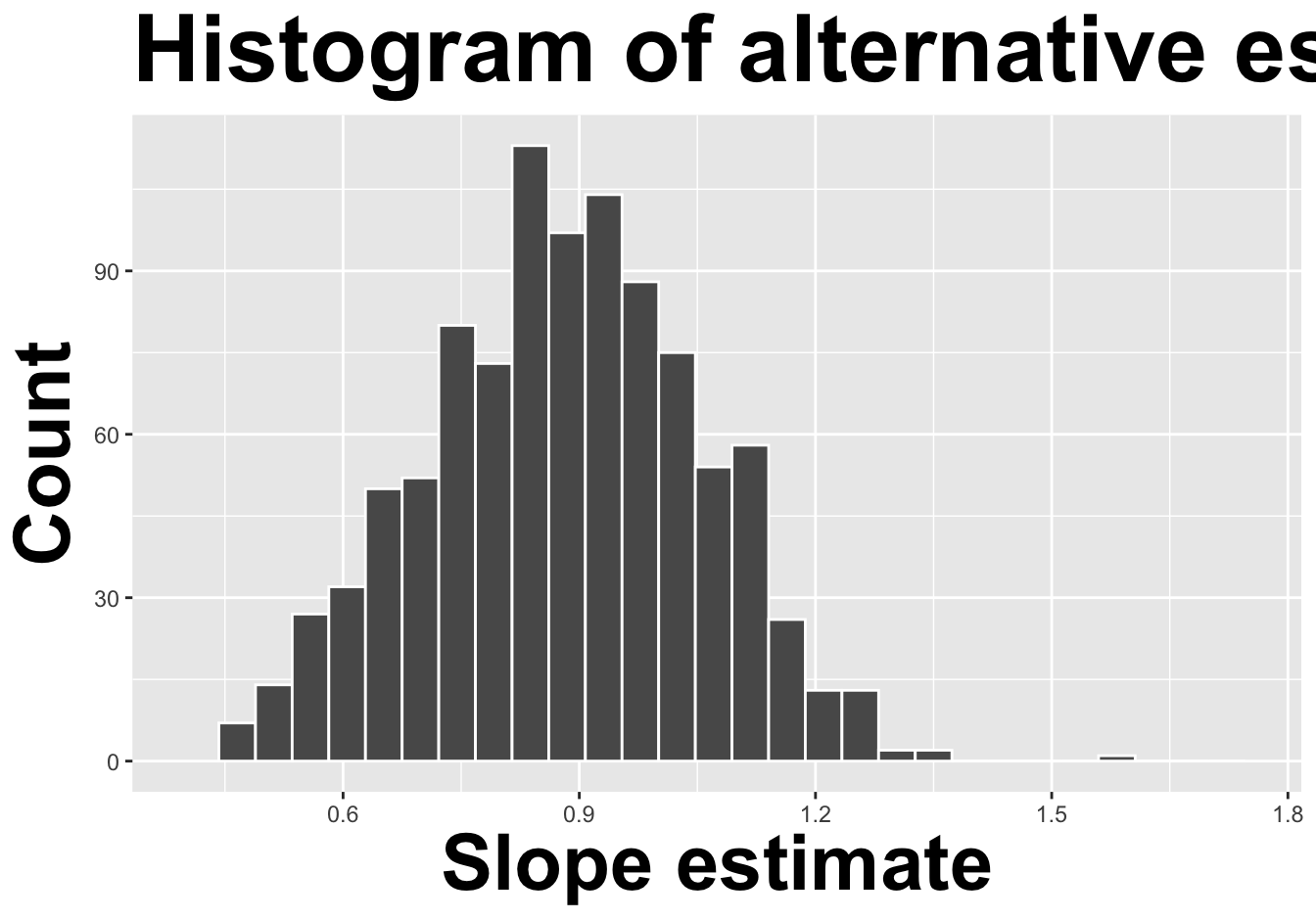
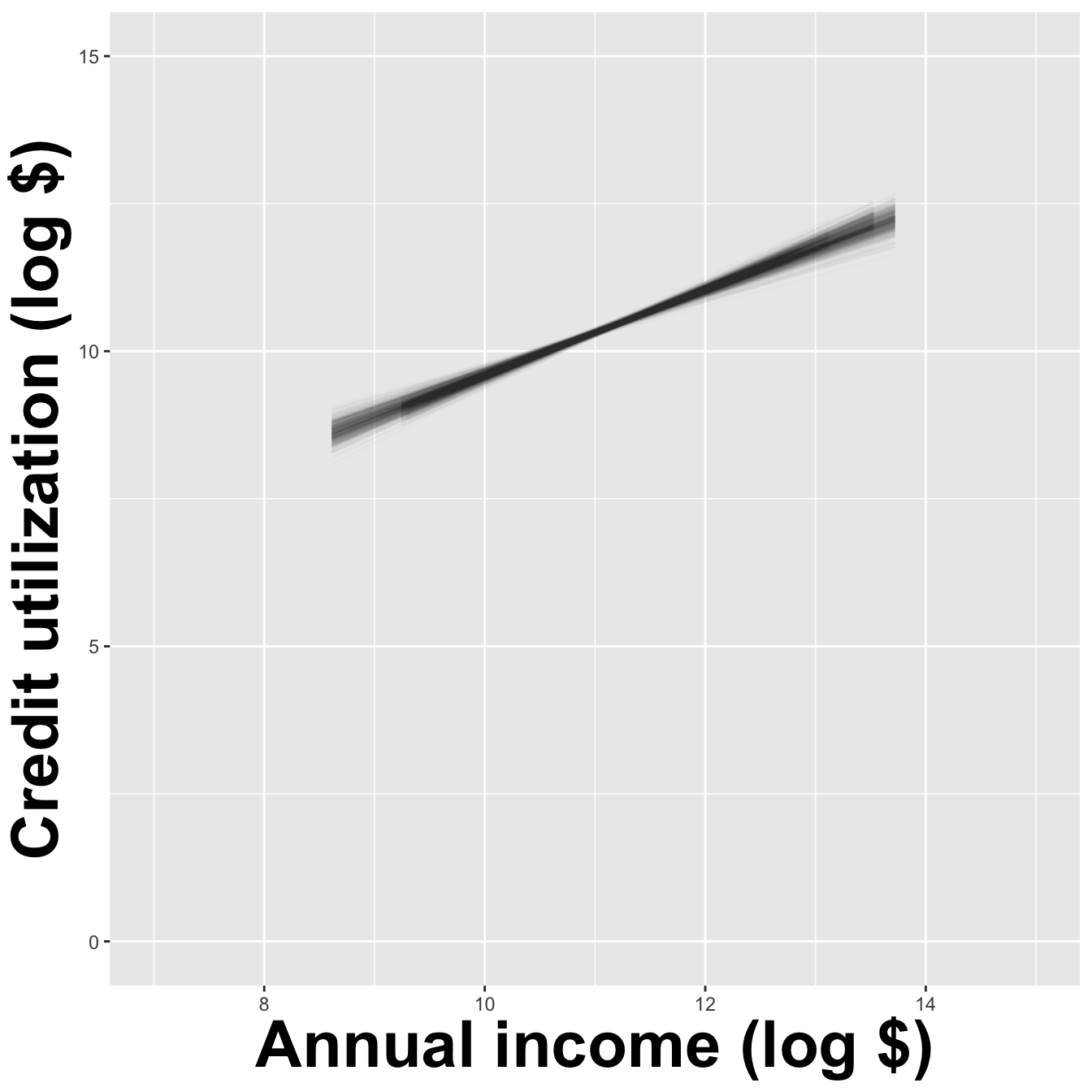
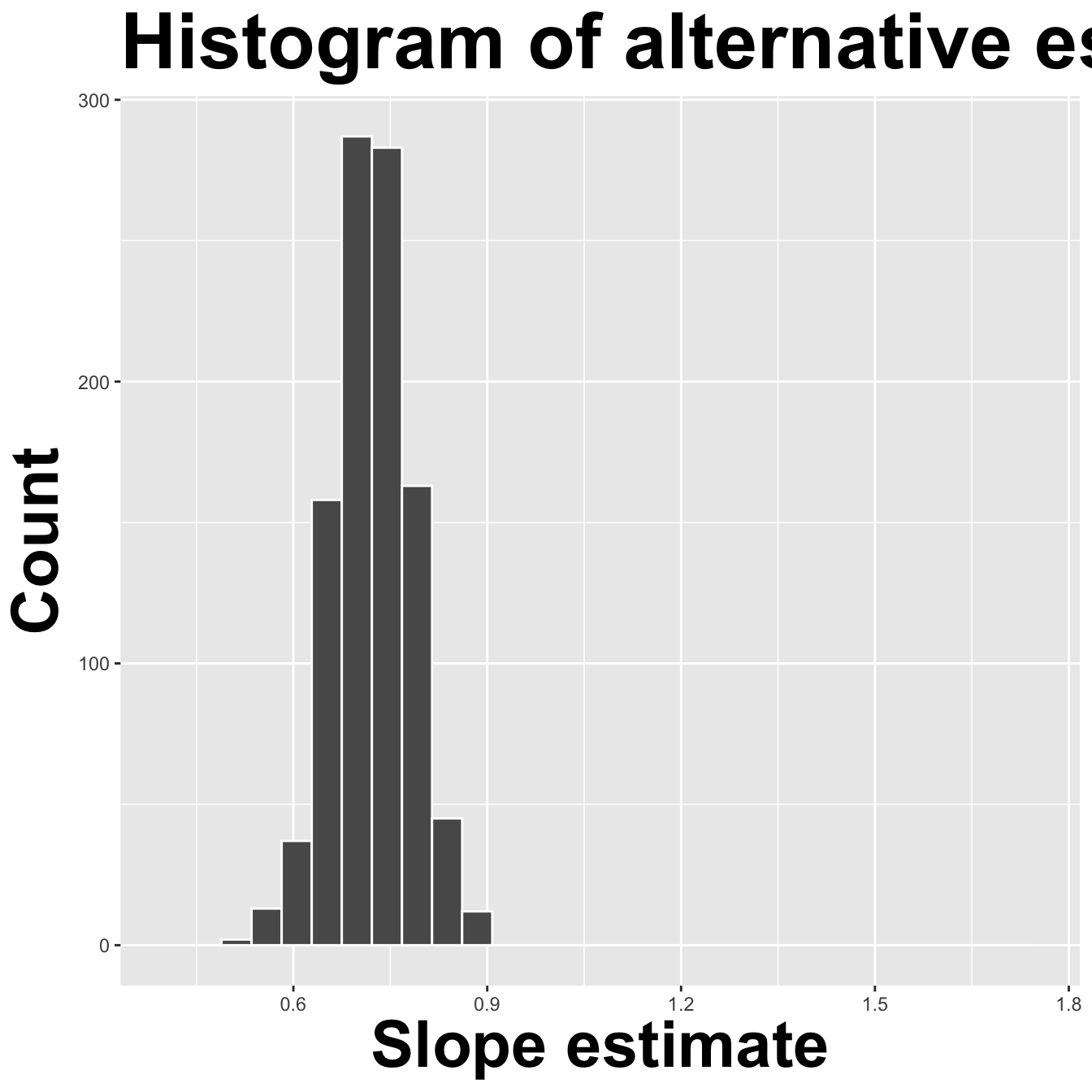

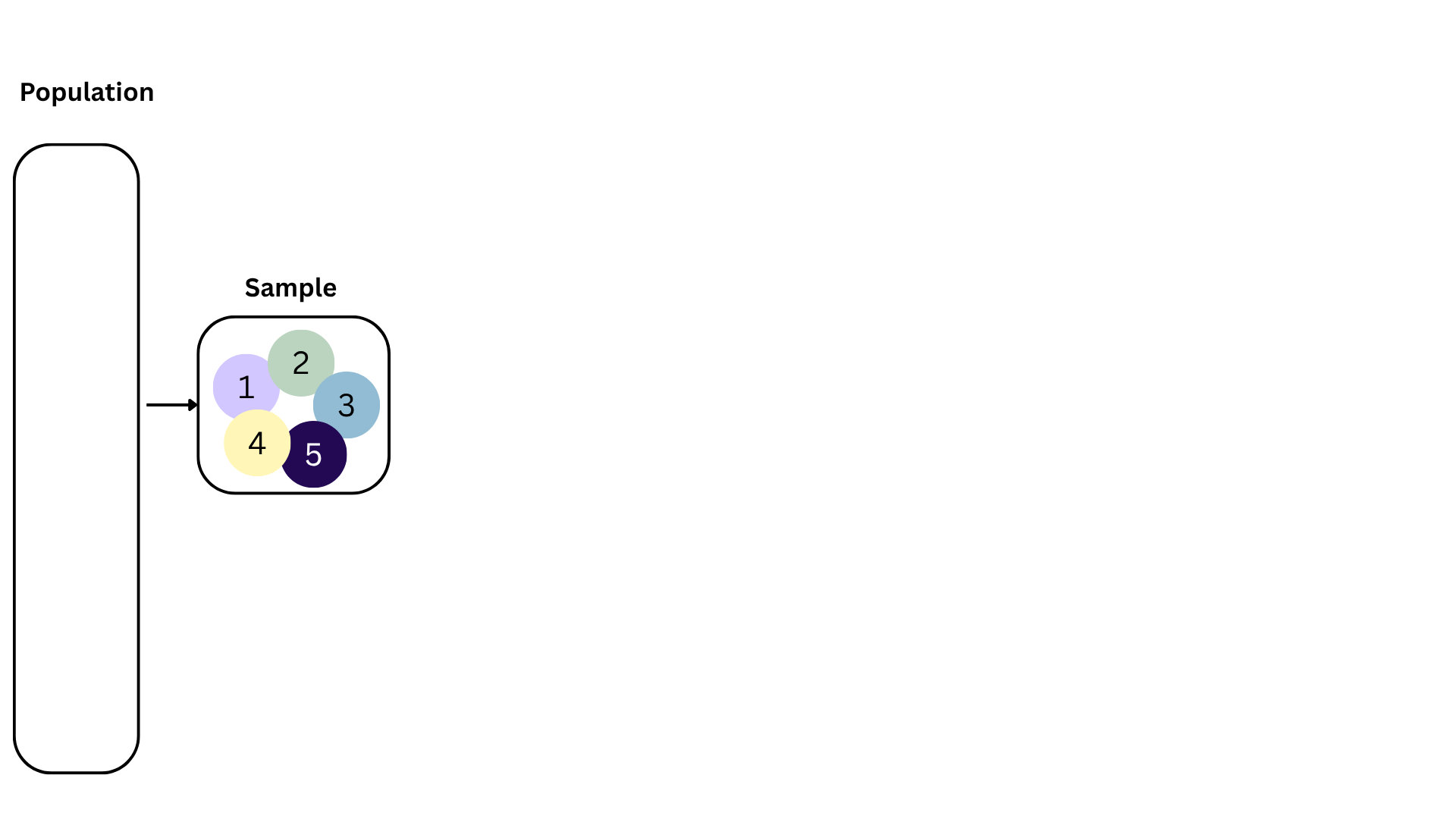
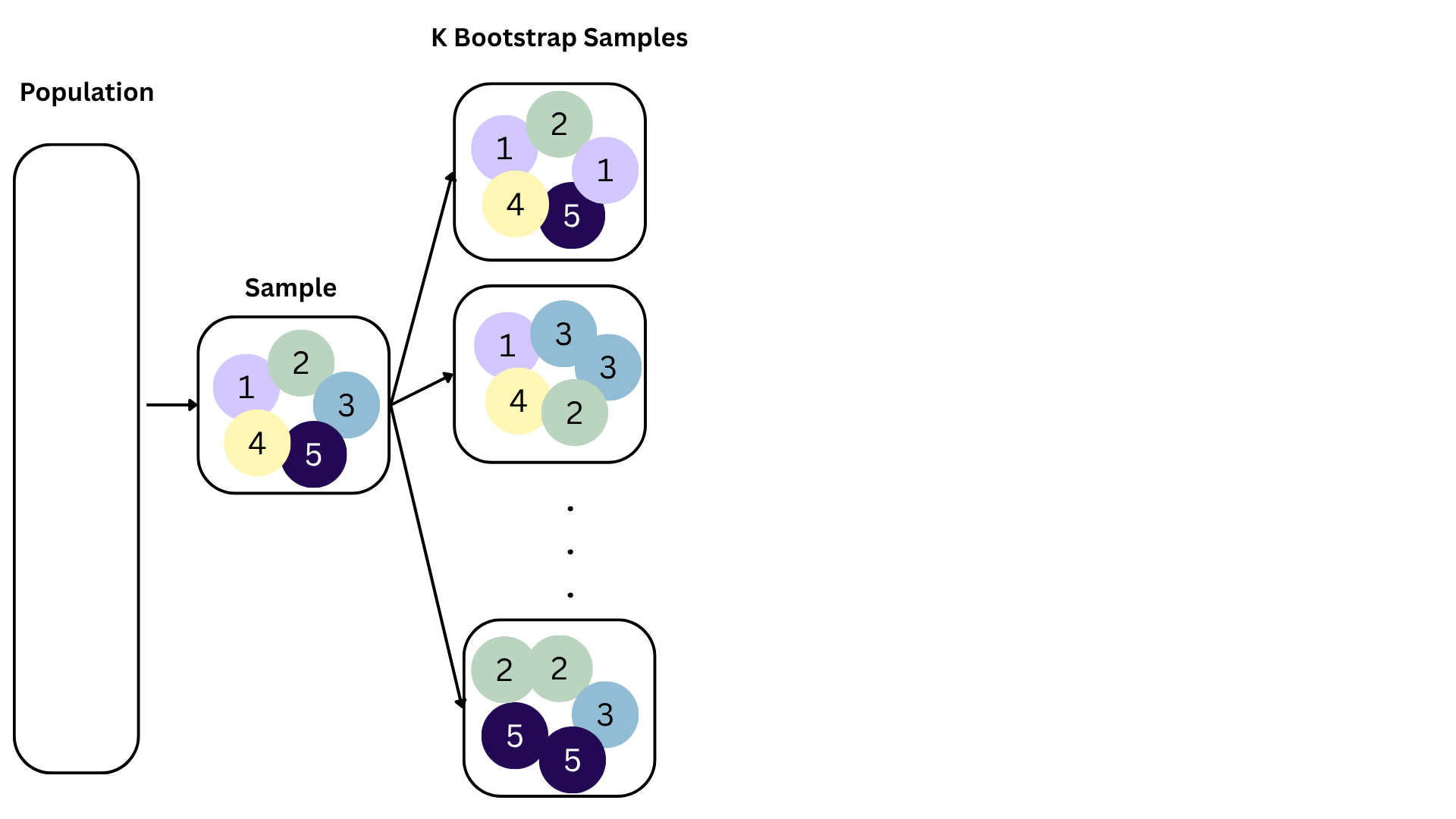
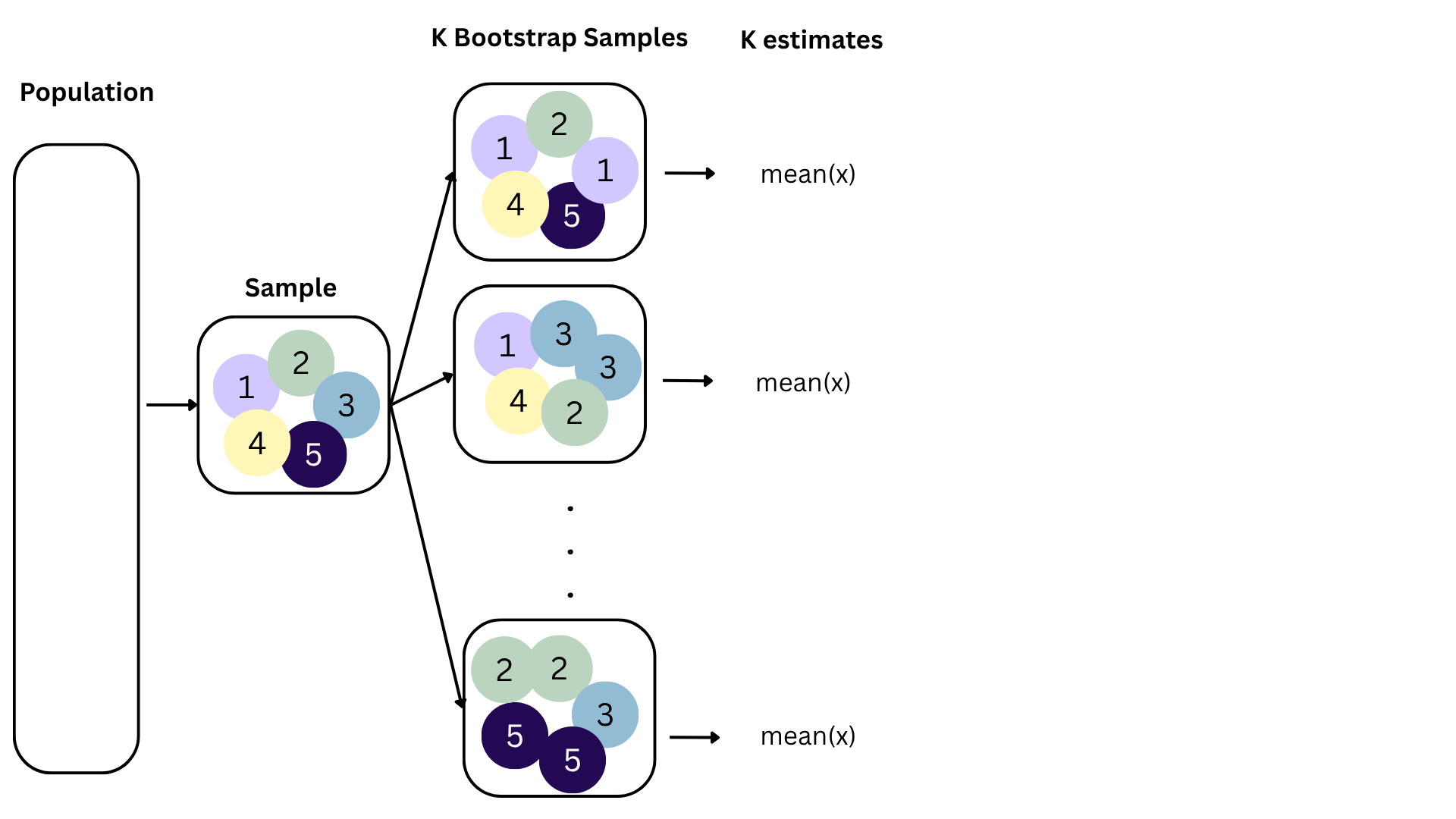
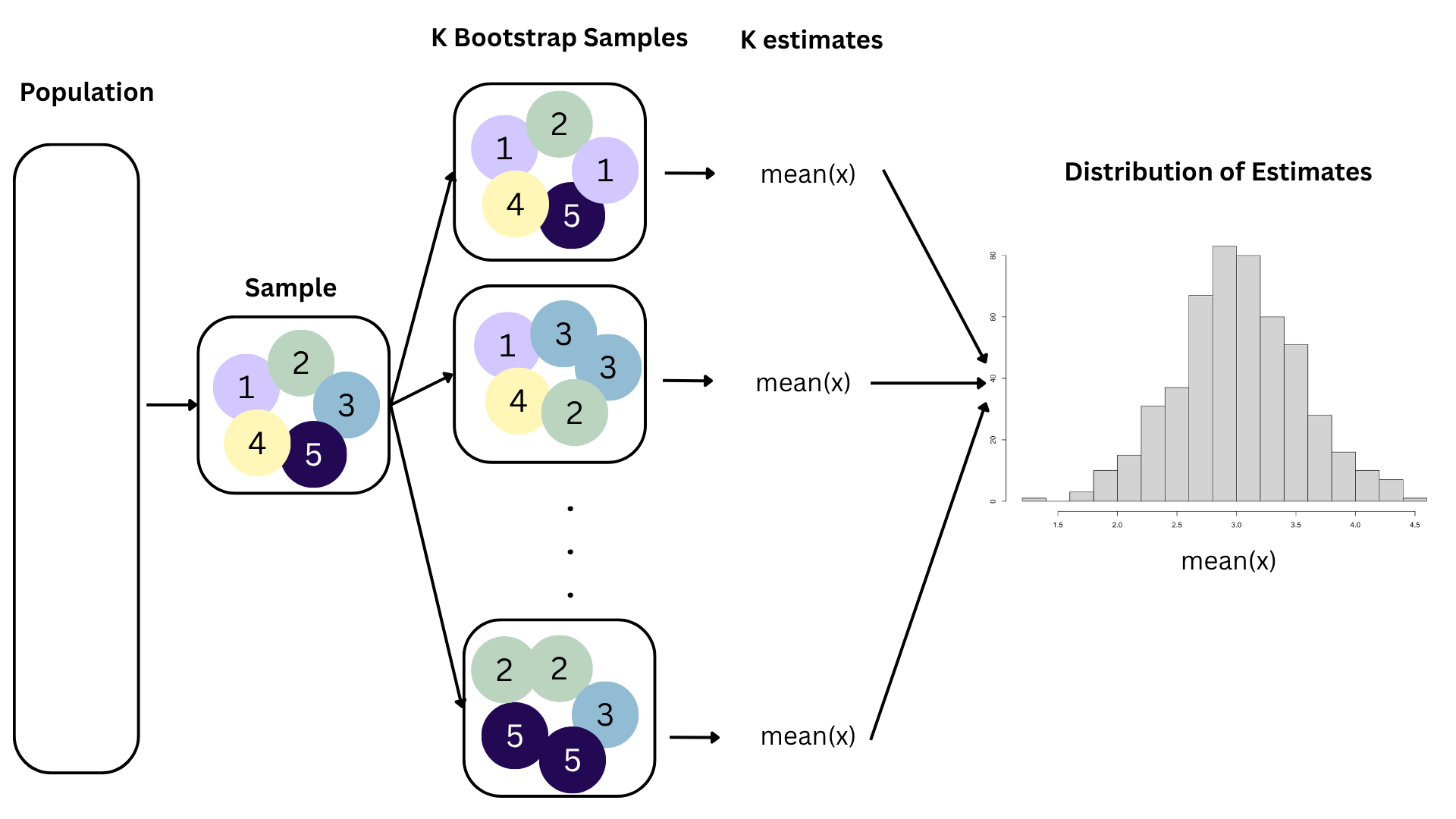
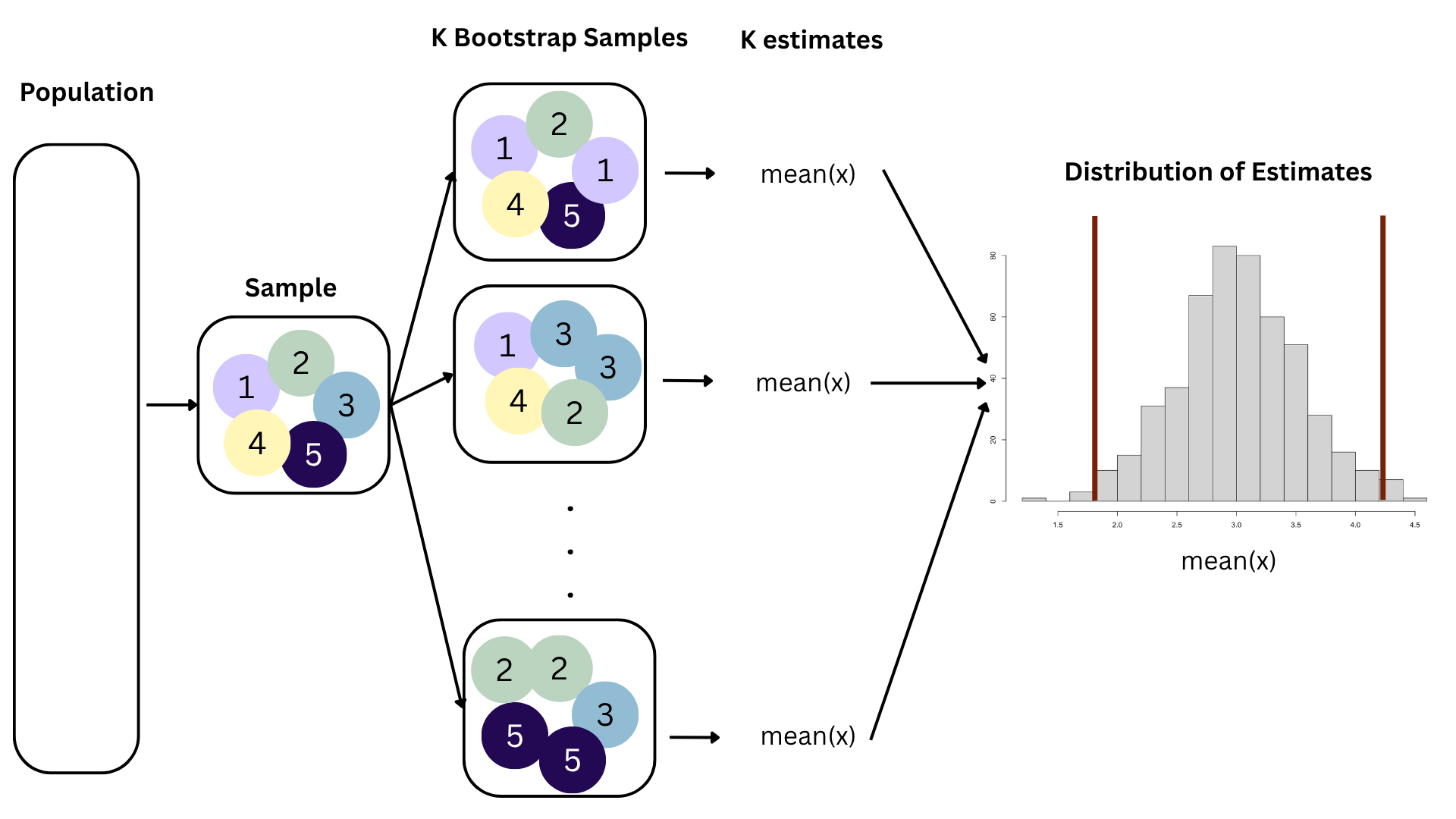
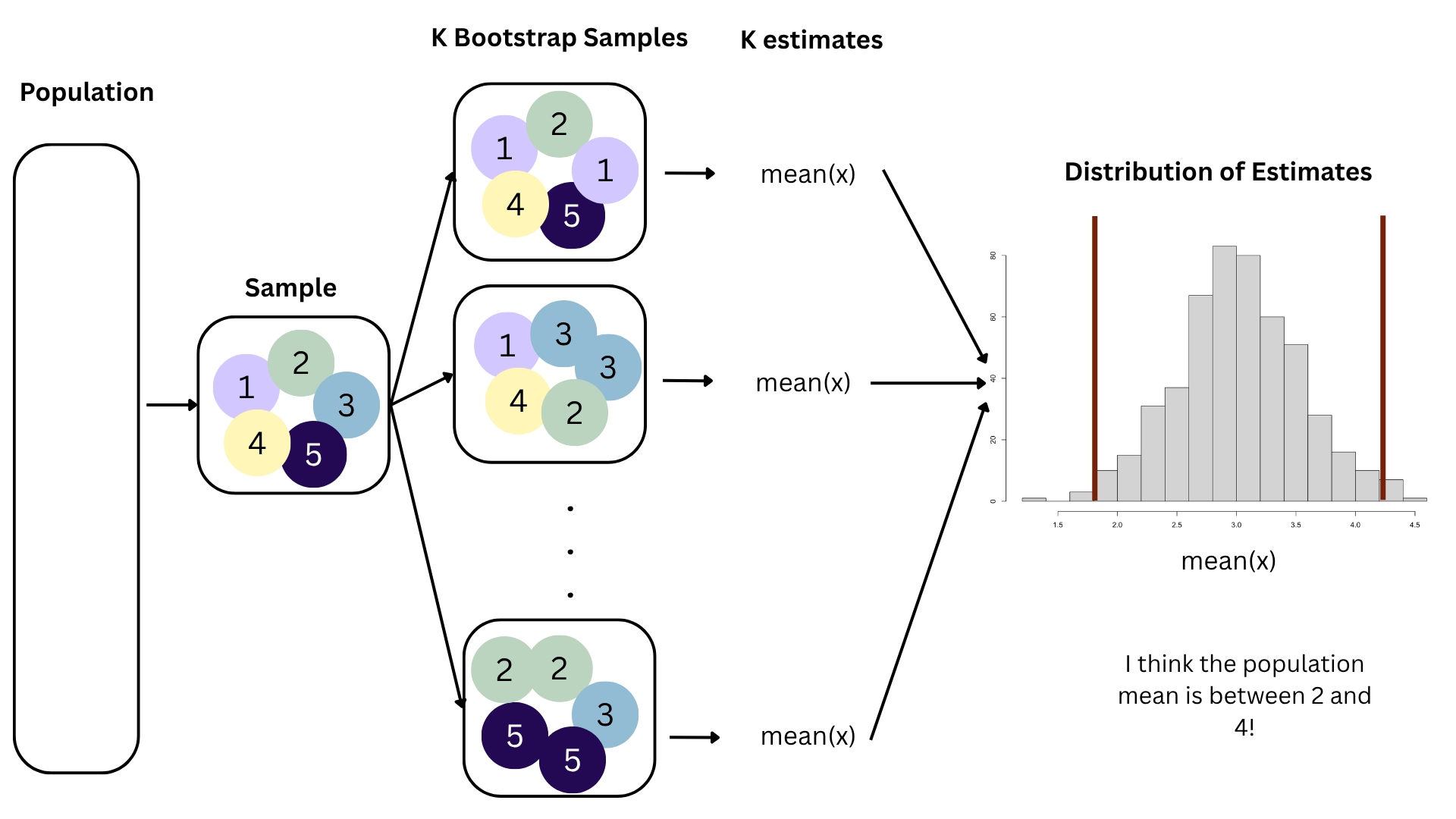

openintro::duke_forest

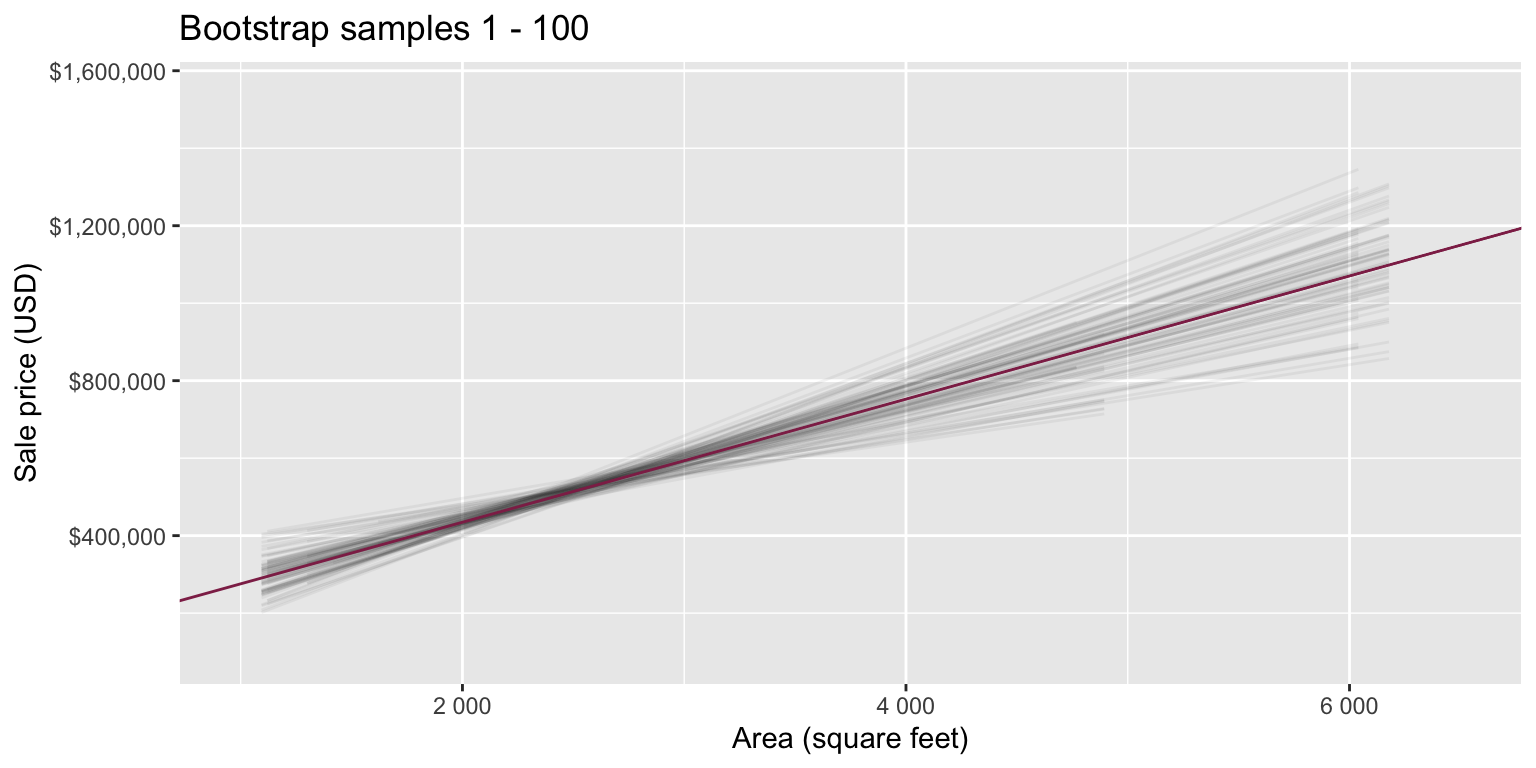
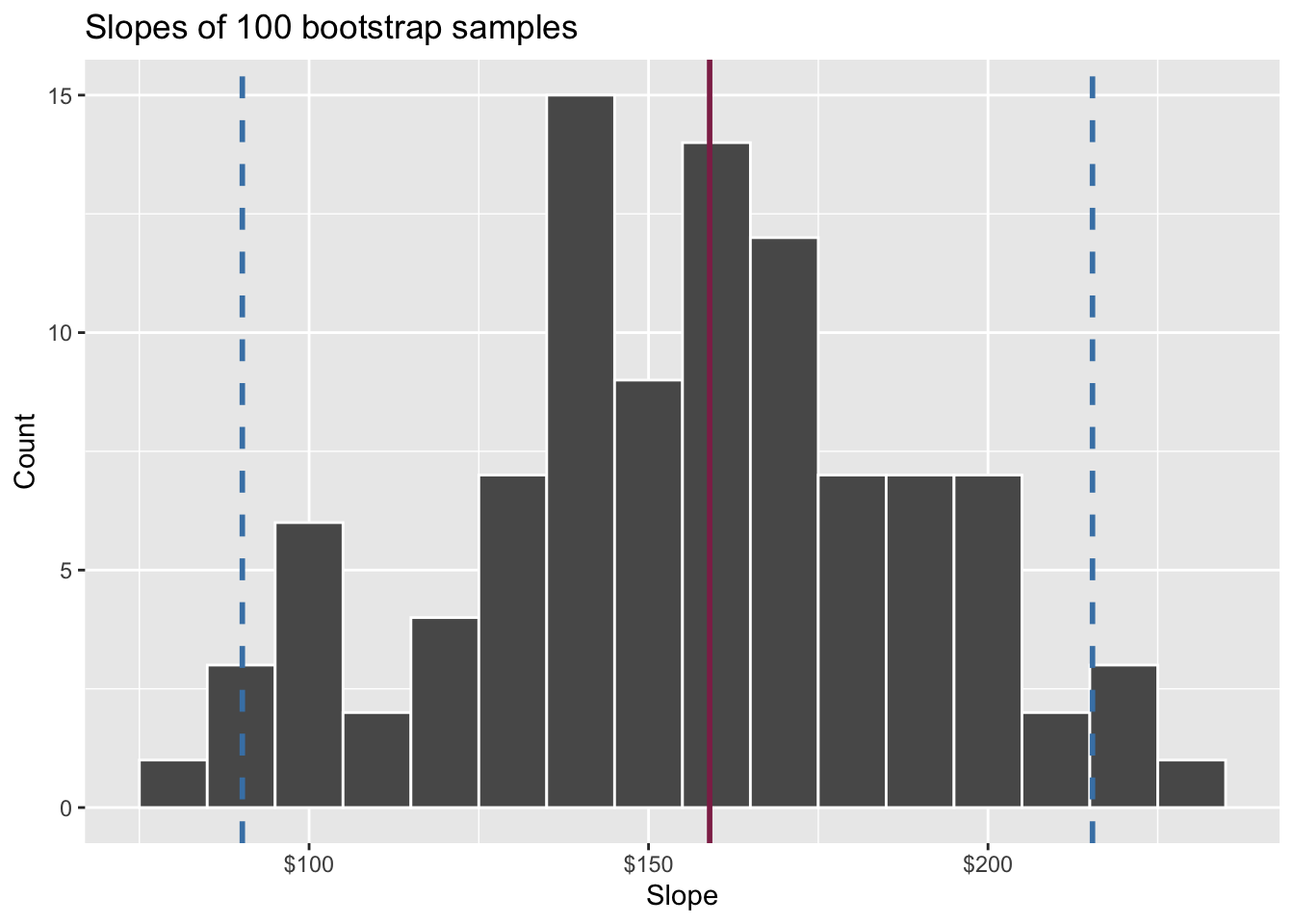
Goal: Use the area (in square feet) to understand variability in the price of houses in Duke Forest.
Fill in the blank: For each additional square foot, the model predicts the sale price of Duke Forest houses to be higher, on average, by between ___ and ___ dollars.
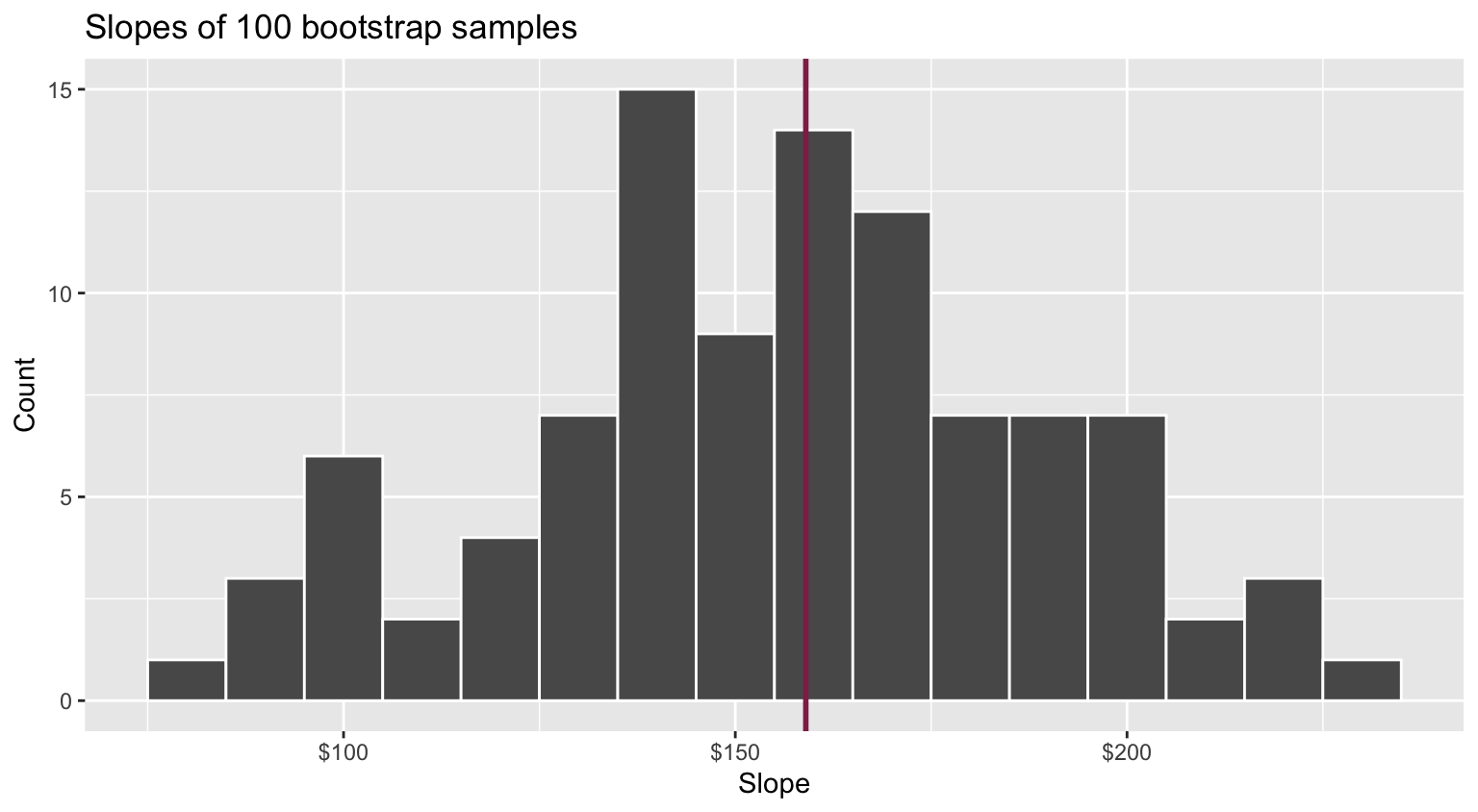
Fill in the blank: For each additional square foot, we expect the sale price of Duke Forest houses to be higher, on average, by between ___ and ___ dollars.
Type 1 error: False positive
Type 2 error: False negative

Which is worse, Type 1 or Type 2 error?
Note: \(H_0\) person innocent vs \(H_A\) person guilty.

Aspects of the American trial system regard a Type 1 error as worse than a Type 2 error (reasonable doubt standard, unanimous juries, presumption of innocence, etc).
Which is worse, Type 1 or Type 2 error? Which are doctors more prone to?
Note: \(H_0\) person well vs \(H_A\) person sick.