Data Ethics
Lecture 12
June 1, 2025
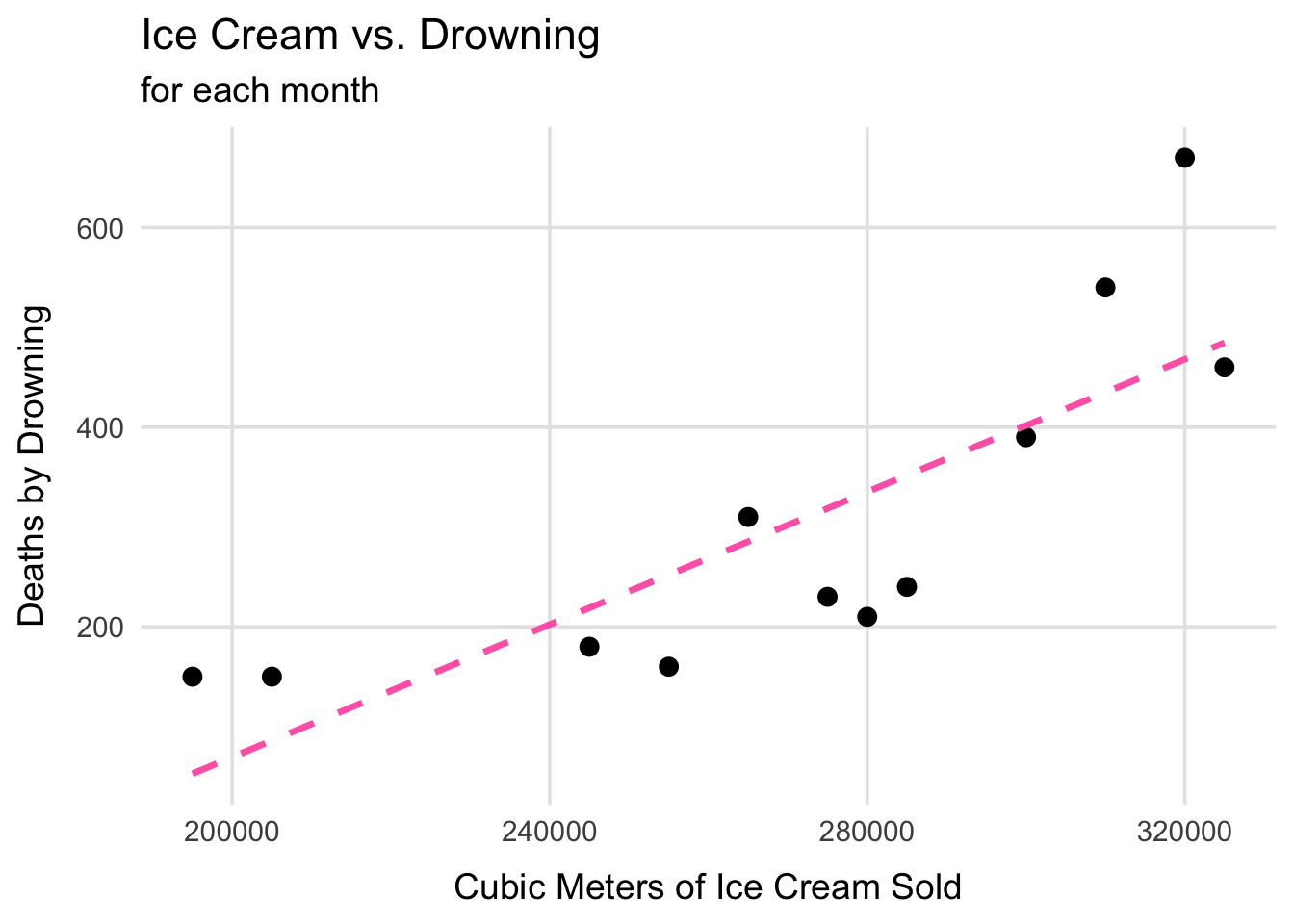
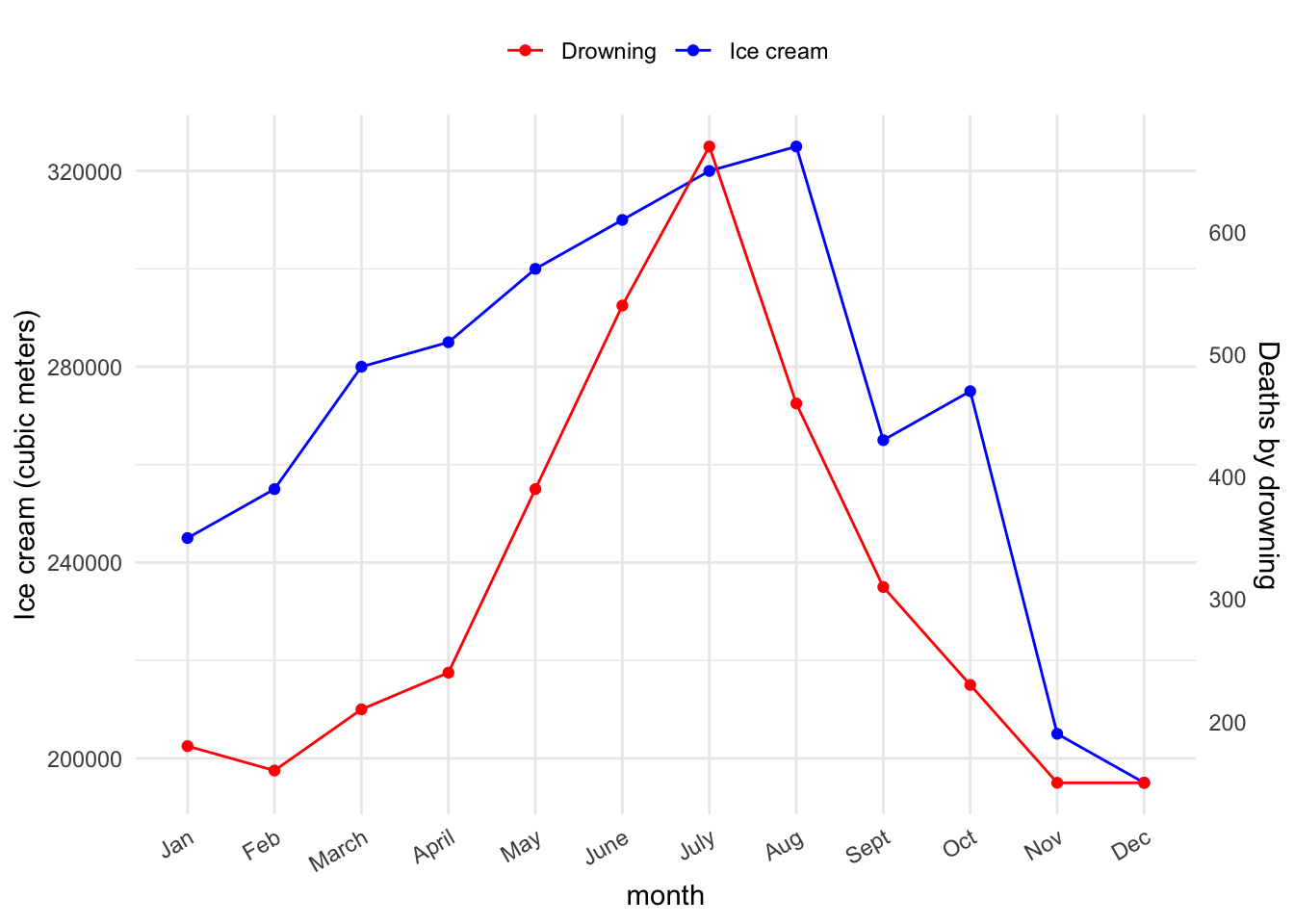
Causality: Ice Cream and Drowning
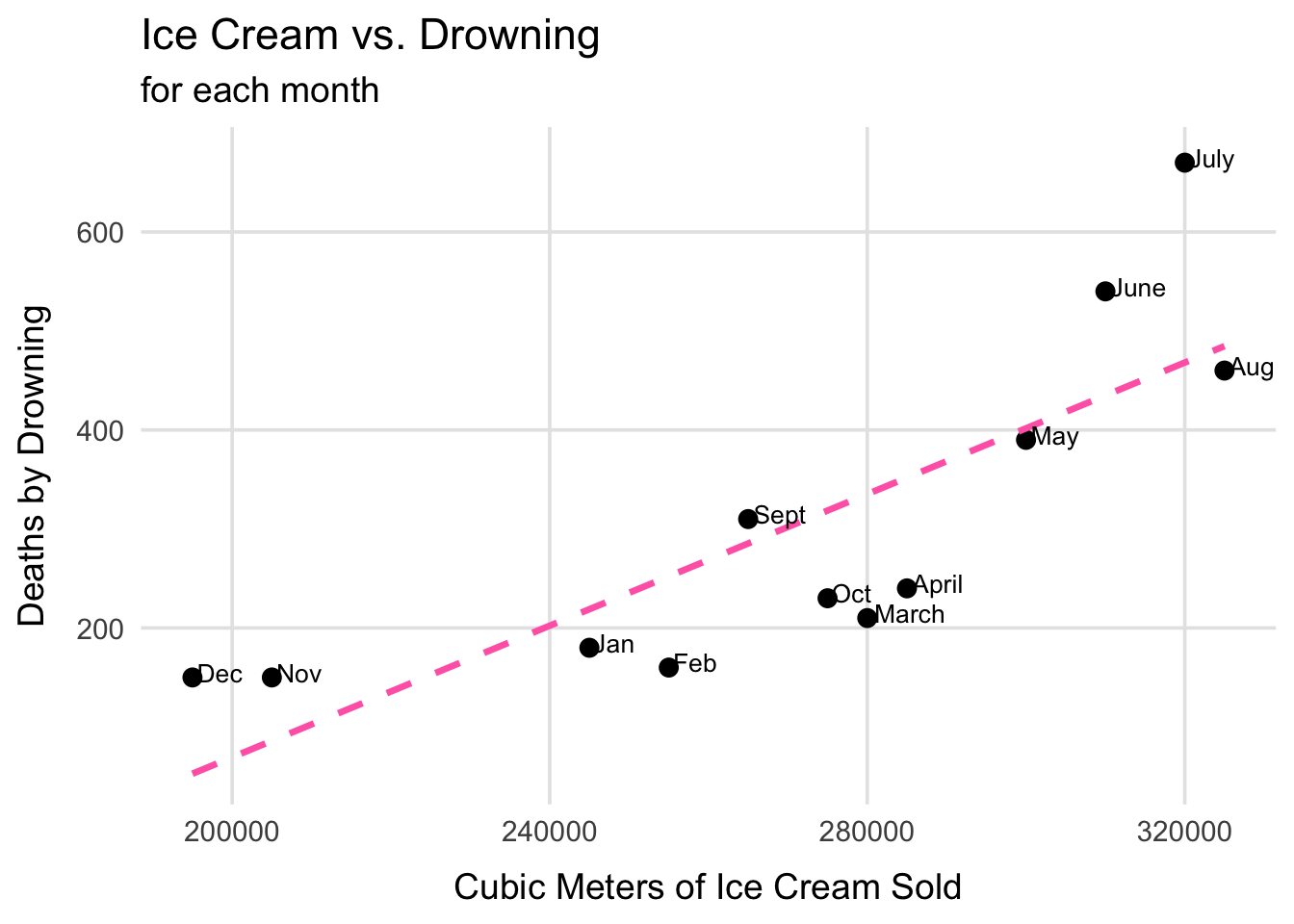
Causality: Ice Cream and Drowning
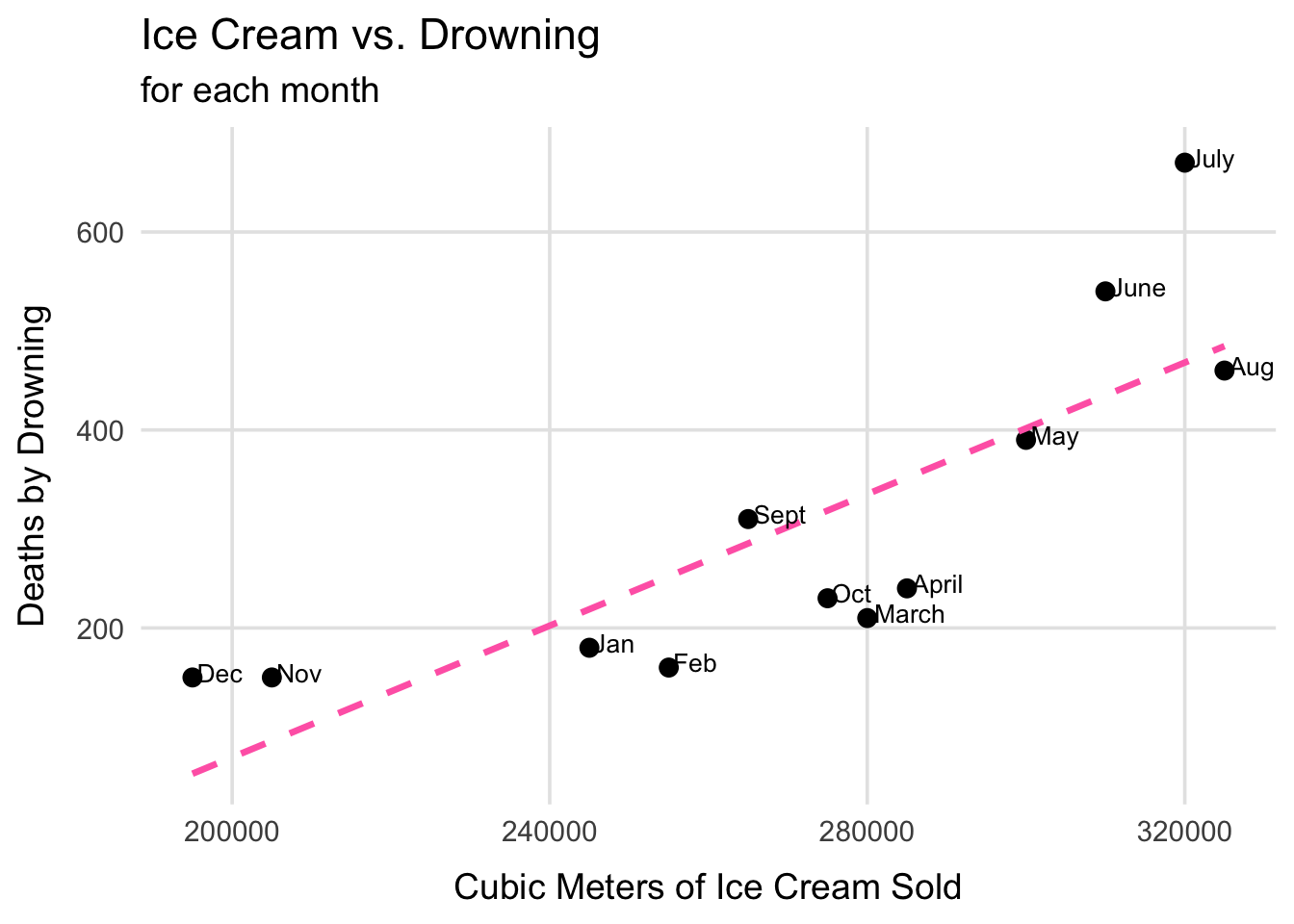
Causality: Ice Cream and Drowning
Causality - TIME coverage
How plausible is the statement in the title of this article?

Causality - LA Times coverage
What does “research shows” mean?

Remember this?
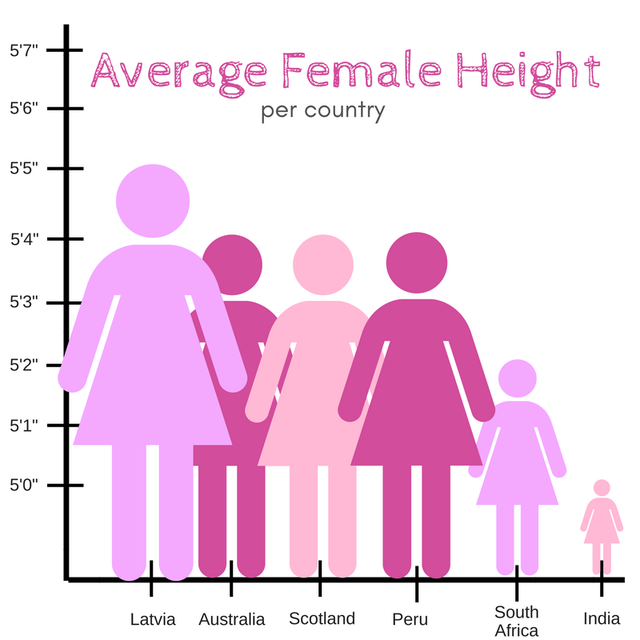
Axes and scales - Tax cuts
What is the difference between these two pictures? Which presents a better way to represent these data?
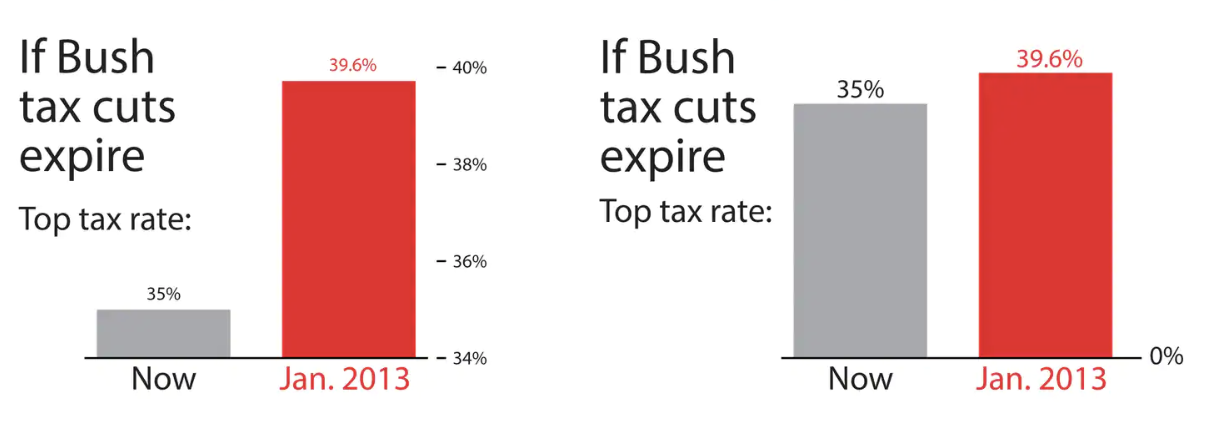
Axes and scales - Cost of gas
What is wrong with this image?
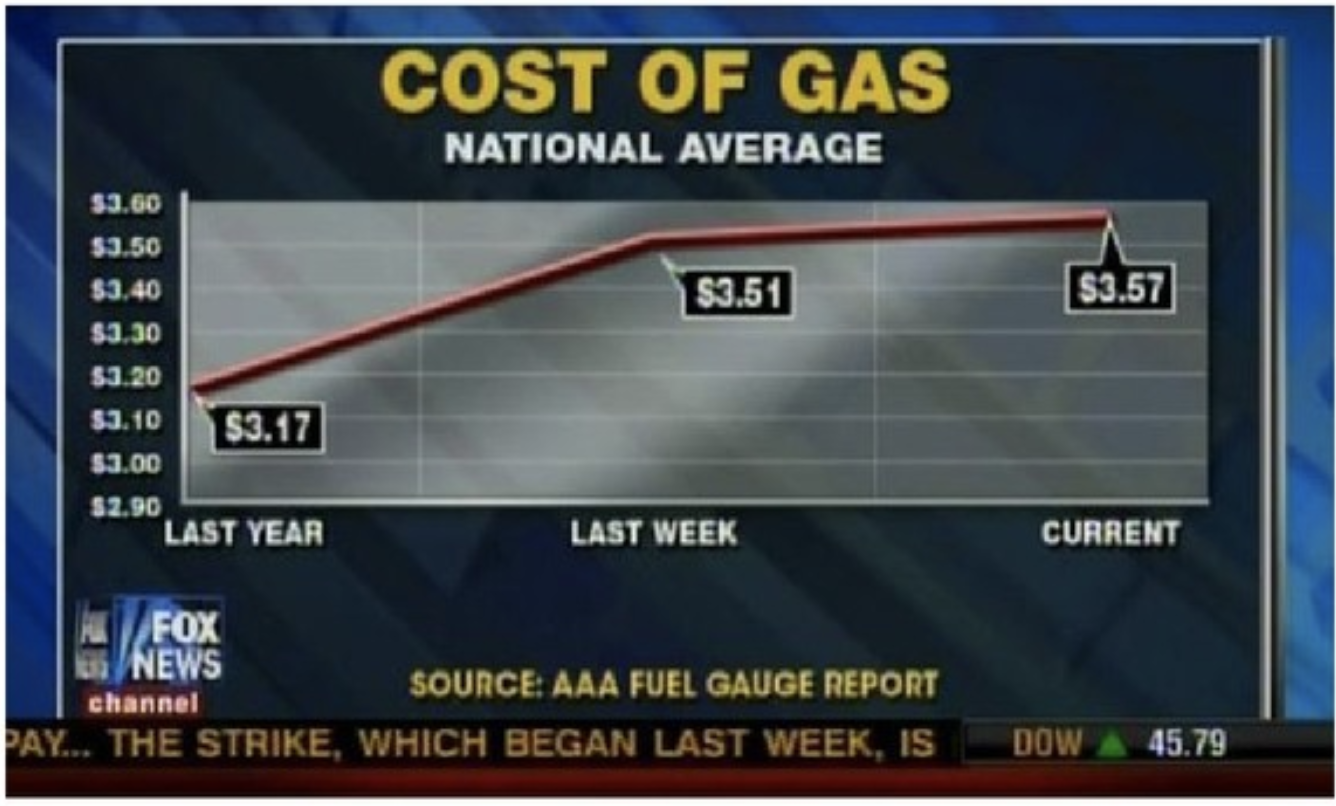
Axes and scales - Cost of gas
df <- tibble(
date = ymd(c("2019-11-01", "2020-10-25", "2020-11-01")),
cost = c(3.17, 3.51, 3.57)
)
ggplot(df, aes(x = date, y = cost, group = 1)) +
geom_point() +
geom_line() +
geom_label(aes(label = cost), hjust = -0.25) +
labs(
title = "Cost of gas",
subtitle = "National average",
x = NULL, y = NULL,
caption = "Source: AAA Fuel Gauge Report"
) +
scale_x_continuous(
breaks = ymd(c("2019-11-01", "2020-10-25", "2020-11-01")),
labels = c("Last year", "Last week", "Current"),
guide = guide_axis(angle = 90),
limits = ymd(c("2019-11-01", "2020-11-29")),
minor_breaks = ymd(c("2019-11-01", "2020-10-25", "2020-11-01"))
) +
scale_y_continuous(labels = label_dollar())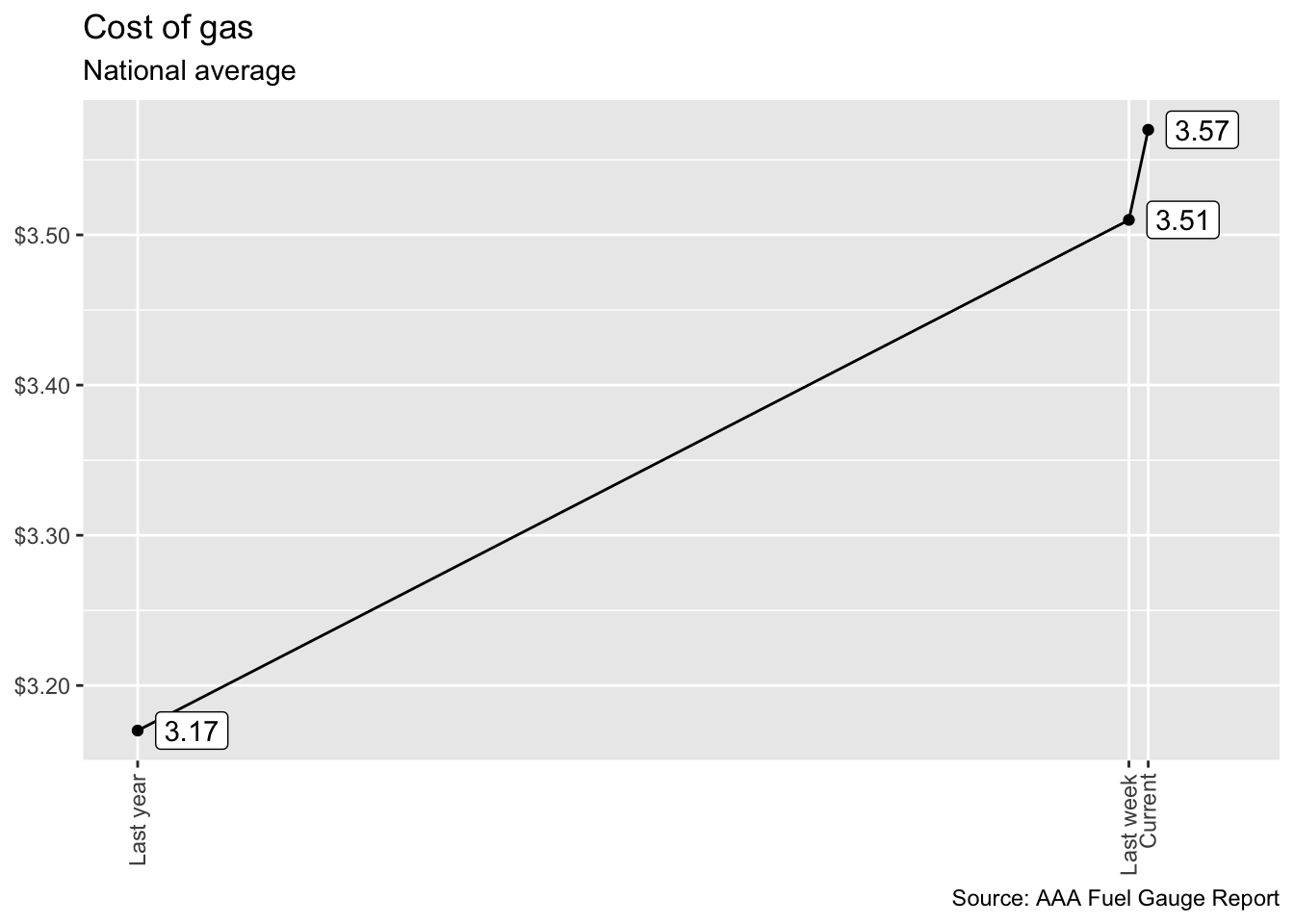
Axes and scales - COVID in GA
What is wrong with this image?
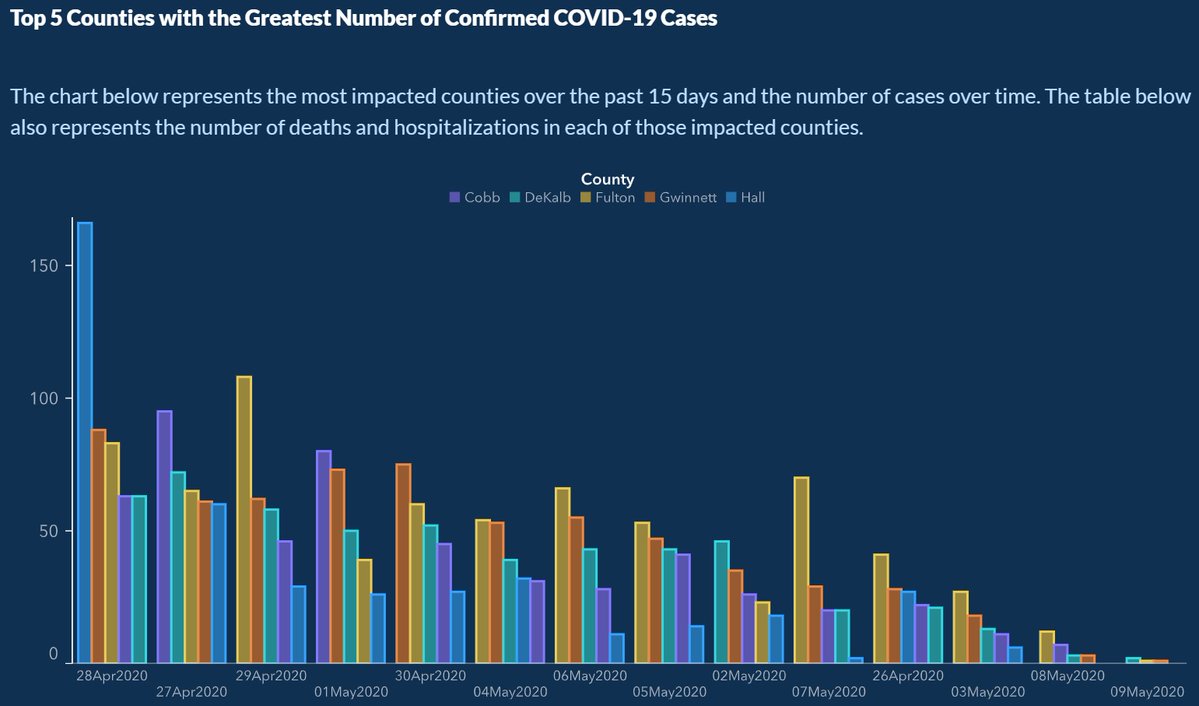
Axes and scales - COVID in GA
Axes and scales - PP services
What is wrong with this picture? How would you correct it?
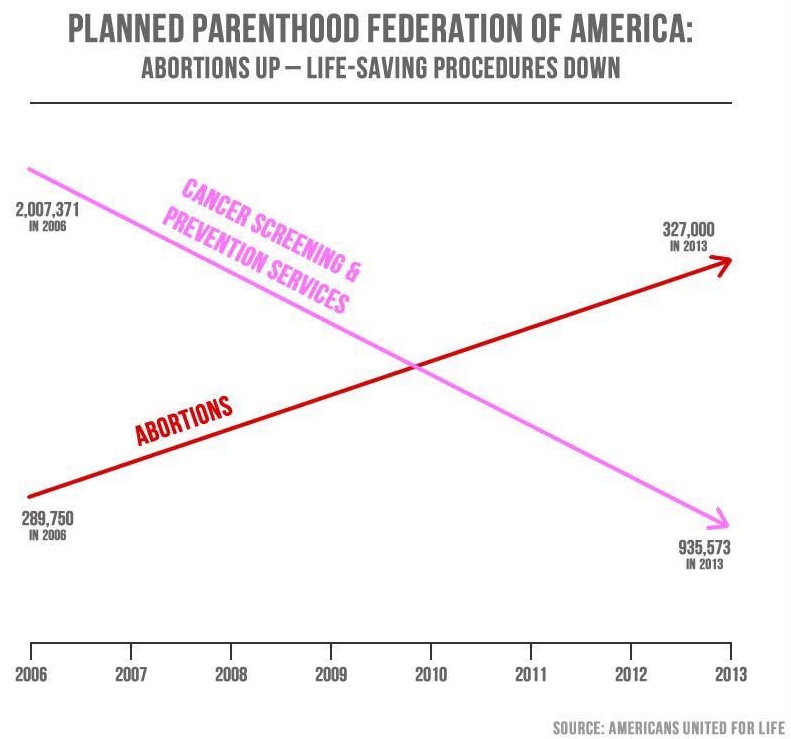
Axes and scales - PP services
pp <- tibble(
year = c(2006, 2006, 2013, 2013),
service = c("Abortion", "Cancer", "Abortion", "Cancer"),
n = c(289750, 2007371, 327000, 935573)
)
ggplot(pp, aes(x = year, y = n, color = service)) +
geom_point(size = 2) +
geom_line(linewidth = 1) +
geom_text(aes(label = n), nudge_y = 100000) +
geom_text(
aes(label = year),
nudge_y = 200000,
color = "darkgray"
) +
labs(
title = "Services provided by Planned Parenthood",
caption = "Source: Planned Parenthood",
x = NULL,
y = NULL
) +
scale_x_continuous(breaks = c(2006, 2013)) +
scale_y_continuous(labels = label_number(big.mark = ",")) +
scale_color_manual(values = c("darkred", "hotpink")) +
annotate(
geom = "text",
label = "Abortions",
x = 2009.5,
y = 400000,
color = "darkred"
) +
annotate(
geom = "text",
label = "Cancer screening\nand prevention services",
x = 2010.5,
y = 1600000,
color = "hotpink"
) +
theme_minimal() +
theme(legend.position = "none")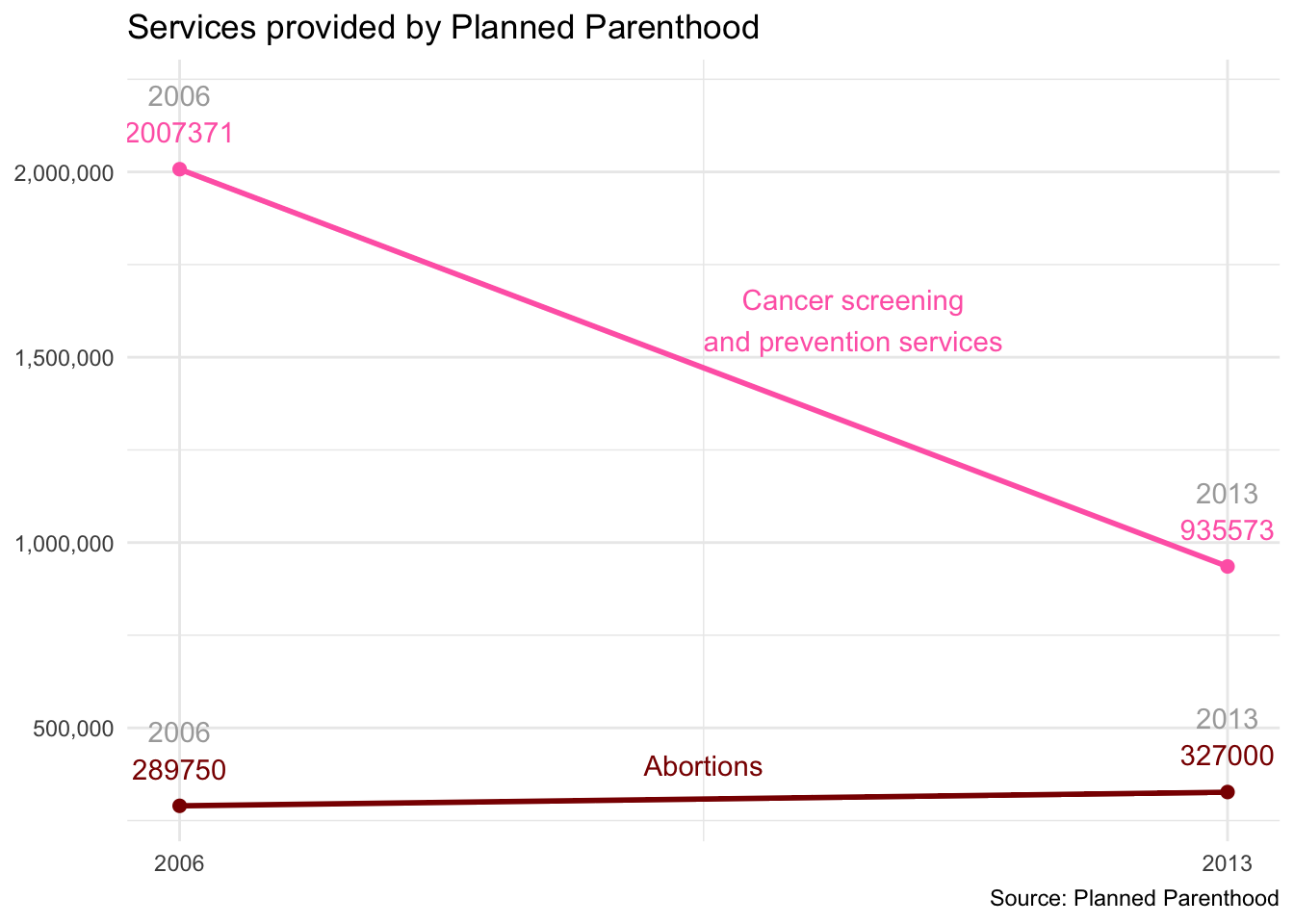
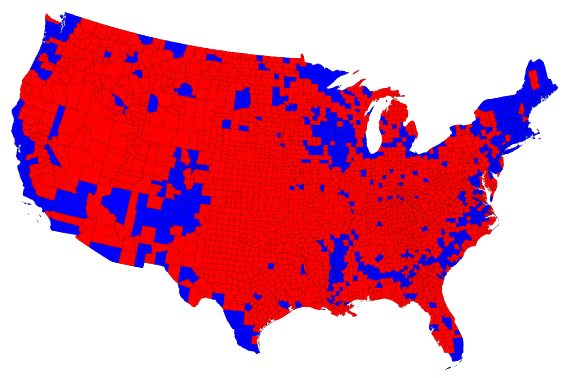
Maps and areas - Voting map
Do you recognize this map? What does it show?
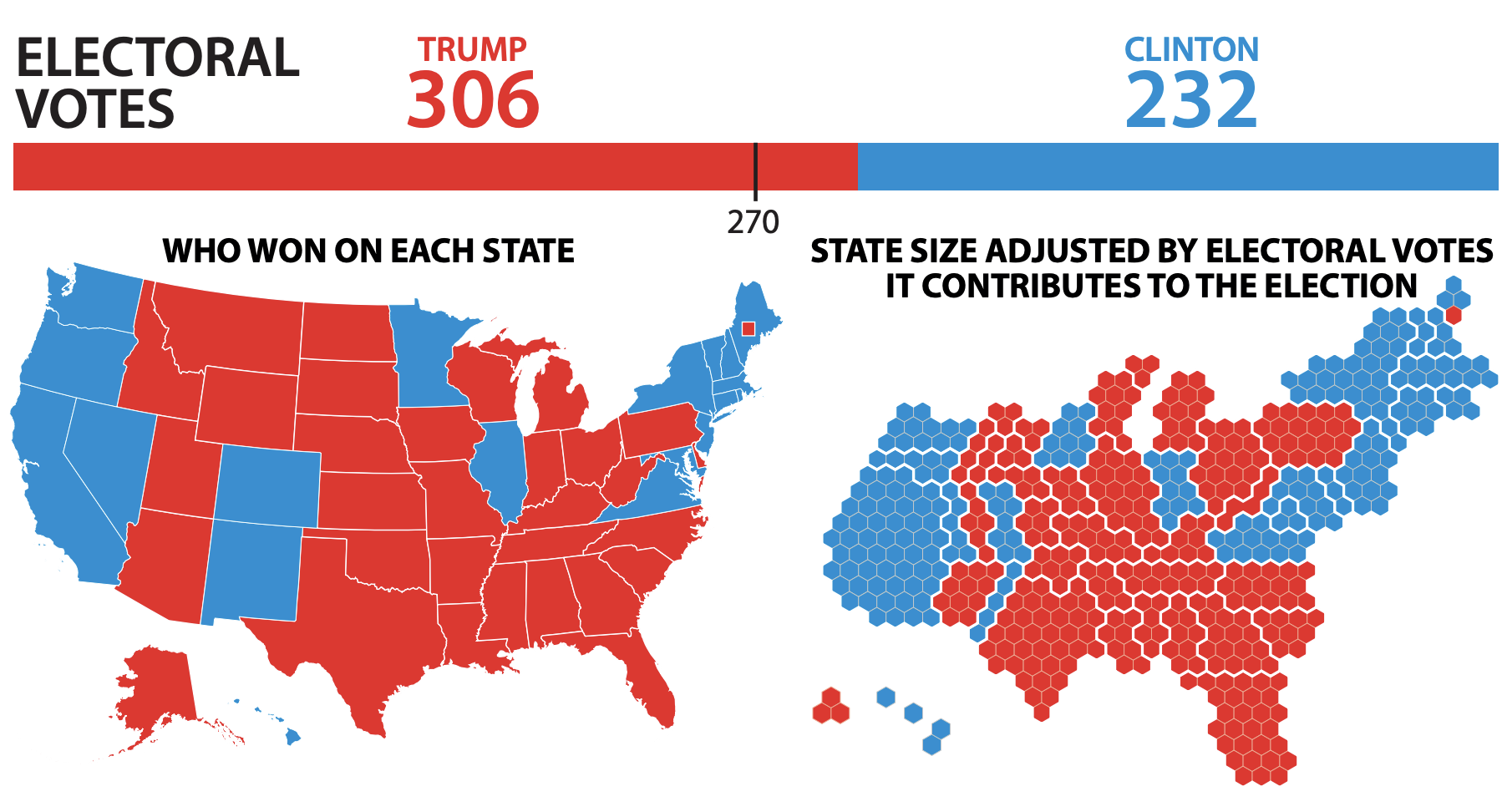
Maps and areas - Voting percentages
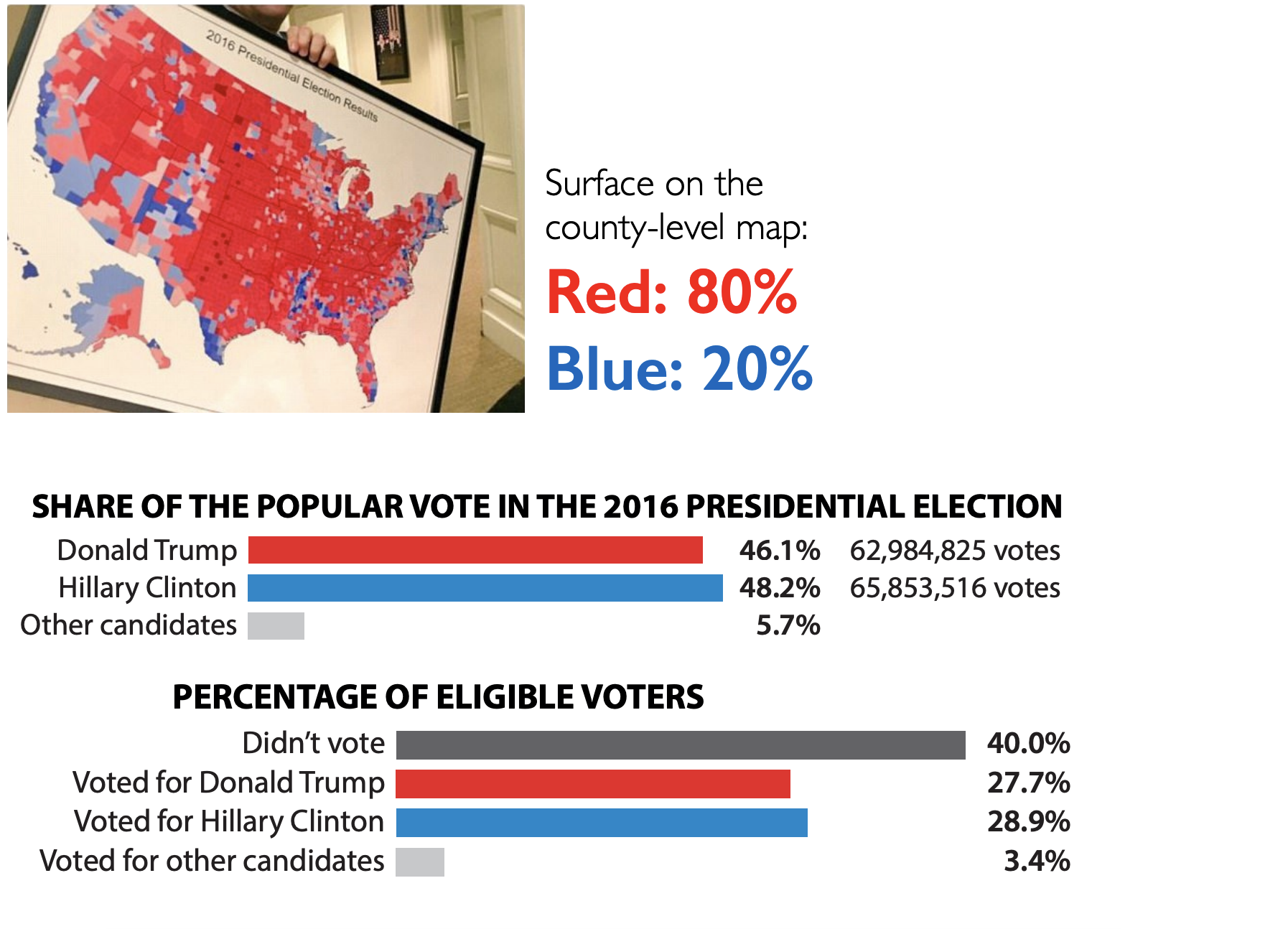
Maps and areas - Voting percentages
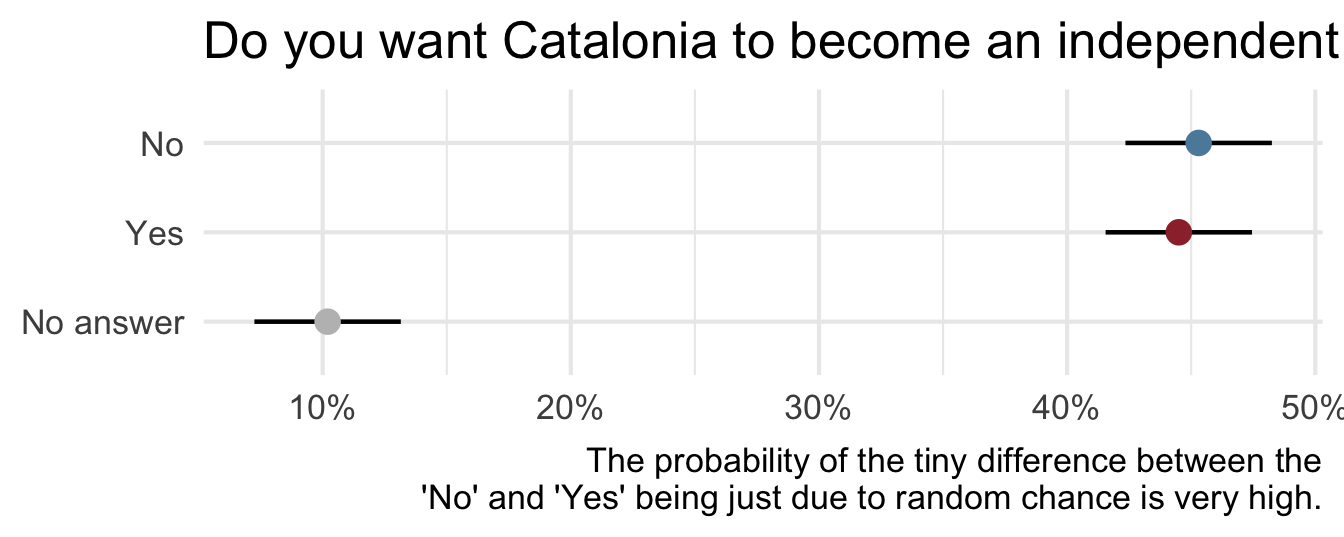
Uncertainty - Catalan independence
On December 19, 2014, the front page of Spanish national newspaper El País read “Catalan public opinion swings toward ‘no’ for independence, says survey”.
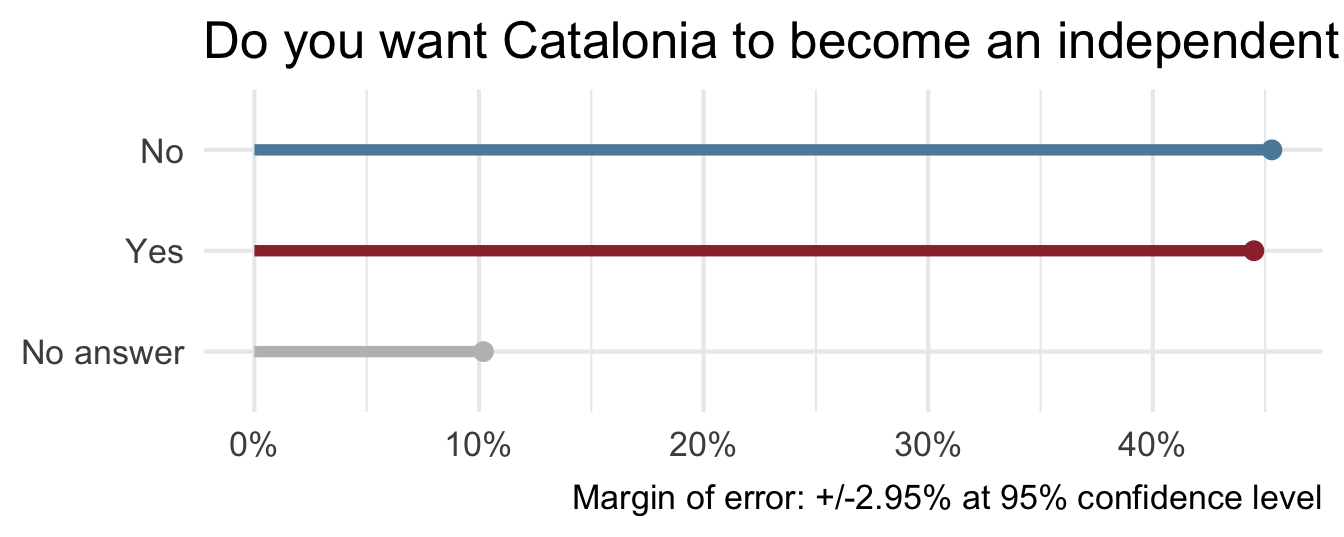
Uncertainty - Catalan independence
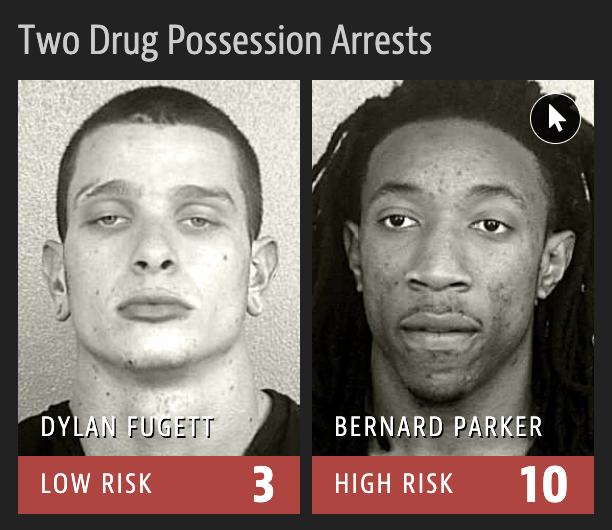
What might “risk assessment” look like?
Something we will study after the midterm:
Above the line means high risk means no bail. Is this progress?
Notice anything?
What is common among the defendants who were assigned a high/low risk score for reoffending?



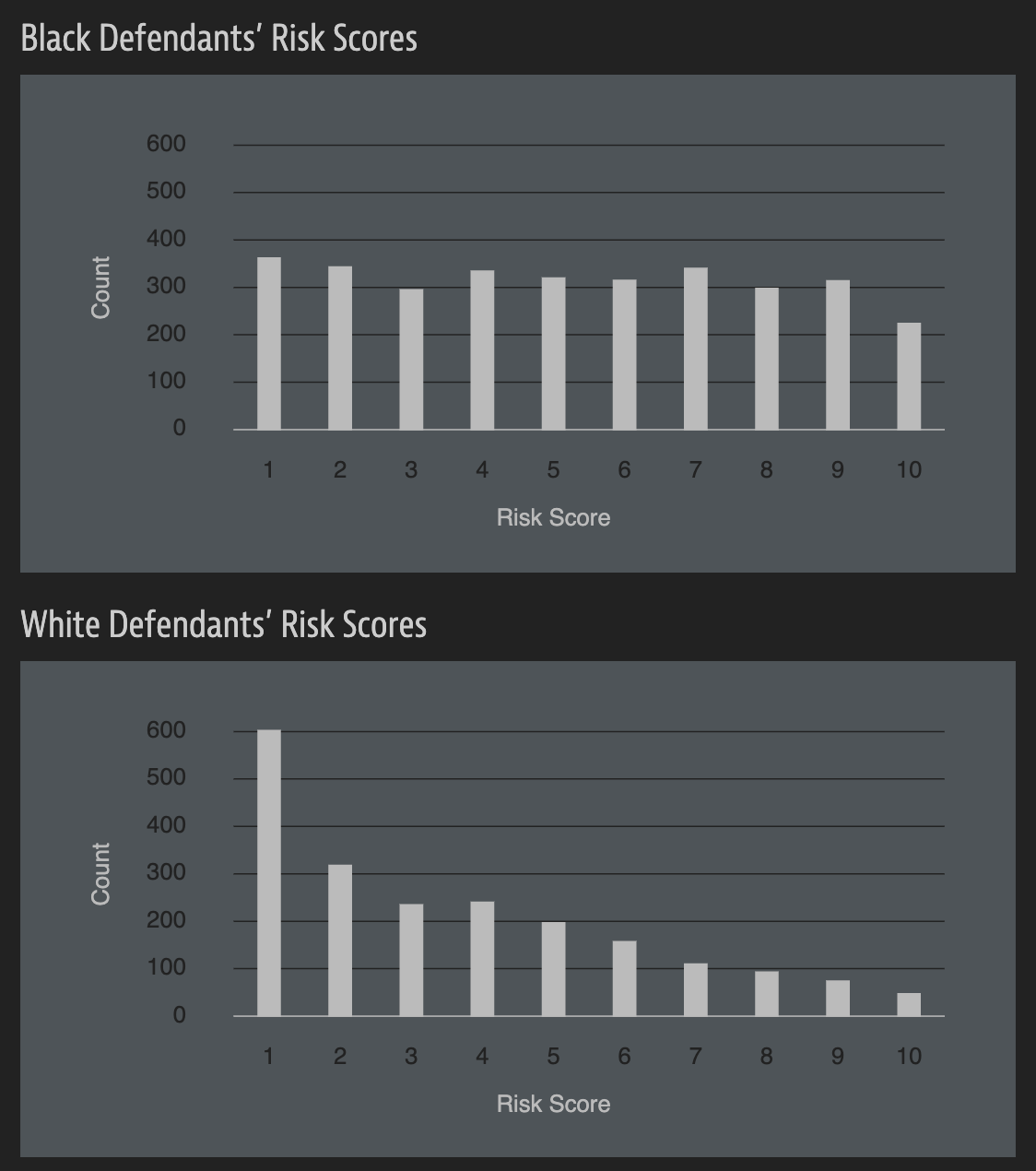
“But race wasn’t in my model”
How can an algorithm that doesn’t use race as input data be racist?
Another algorithmic decision…
 Armies of stats PhDs go to work on these models. They (generally) have no training in the ethics of what they’re doing.
Armies of stats PhDs go to work on these models. They (generally) have no training in the ethics of what they’re doing.
A success story?
Data + Model to predict timing of menstrual cycle:




A perfect microcosm of the themes of our course…
…but what if you learned they were selling your data?
Data privacy

AOL search data leak

OK Cupid data breach

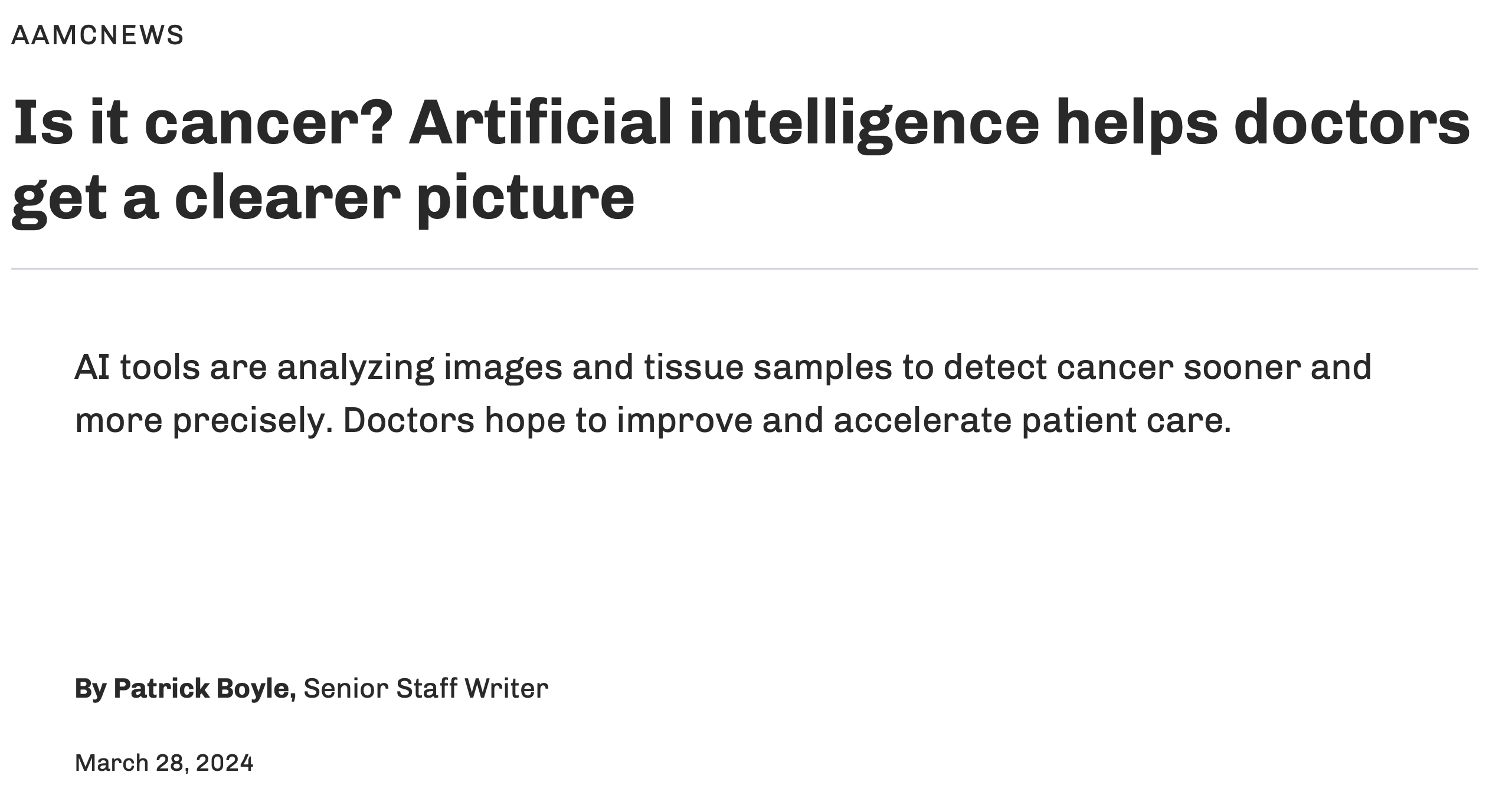
Faster, more accurate cancer screening?
Augmenting doctors’ diagnostic capacity so that they make fewer mistakes, treat more people, and focus on other aspects of care:
The Nobel Prize last year

AlphaFold2: “predicting 3D structures [of proteins] (\(y\)) directly from the primary amino acid sequence (\(x\)).”
“researchers can now better understand antibiotic resistance and create images of enzymes that can decompose plastic.”
How Charts Lie

Calling Bullshit

Calling Bullshit
The Art of Skepticism in a
Data-Driven World
by Carl Bergstrom and Jevin West
Invisible Women

Invisible Women: Data Bias in a World Designed for Men
by Caroline Criado Perez
Machine Bias

by Julia Angwin, Jeff Larson, Surya Mattu, and Lauren Kirchner
Ethics and Data Science

by Mike Loukides, Hilary Mason, DJ Patil
(Free Kindle download)
Weapons of Math Destruction

Weapons of Math Destruction
How Big Data Increases Inequality and Threatens Democracy
by Cathy O’Neil
Algorithms of Oppression

Algorithms of Oppression
How Search Engines Reinforce Racism
by Safiya Umoja Noble