# A tibble: 6 × 2
x y
<dbl> <chr>
1 1 Marie
2 2 Marie
3 3 Katie
4 4 Mary
5 5 Mary
6 6 Mary Midterm + More Practice!
Lecture 10
May 29, 2025
Example in-class question
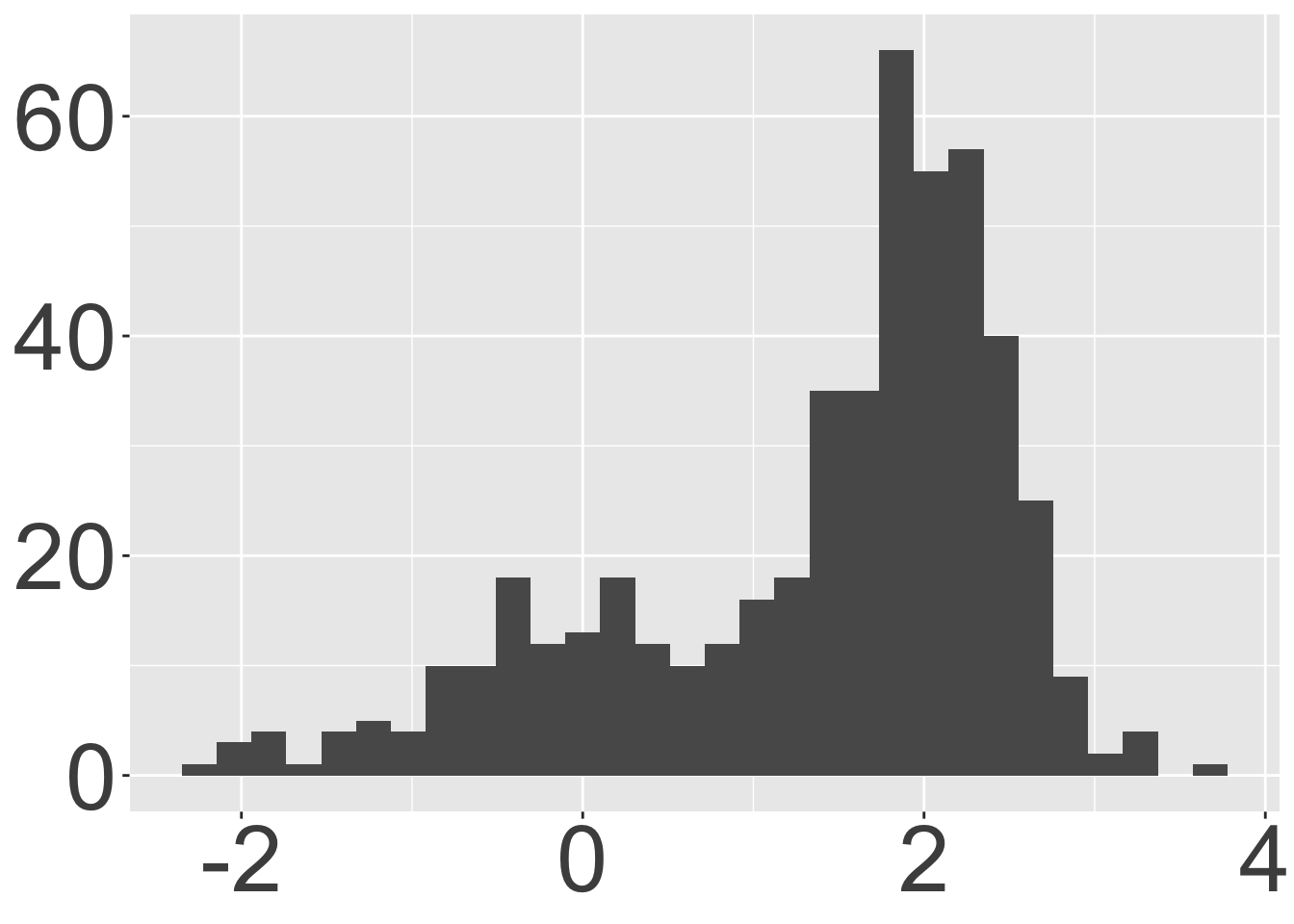
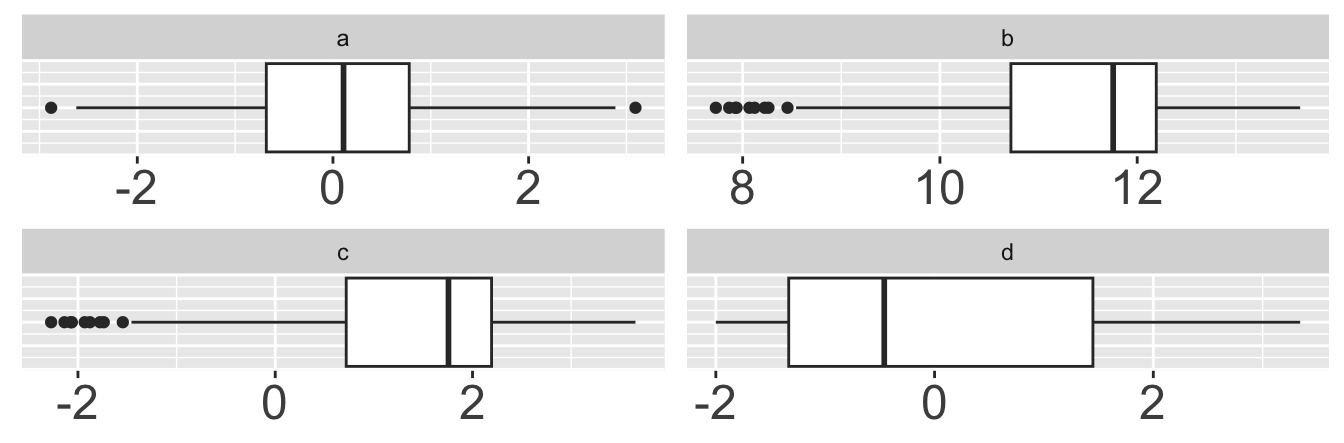
Which box plot is visualizing the same data as the histogram?
Goal 1: Transform Sales Data
Yesterday: read an Excel file with non-tidy data

Goal 1: Transform Sales Data
Yesterday: read an Excel file with non-tidy data
Goal 1: Transform Sales Data
Goal: tidy up the data


String Functions
We’ve seen lots of functions that deal with numeric data (mean, median, sum, etc.) - what about characters?
stringr is a tidyverse package with lots of functions for dealing with character strings
today: str_detect in stringr

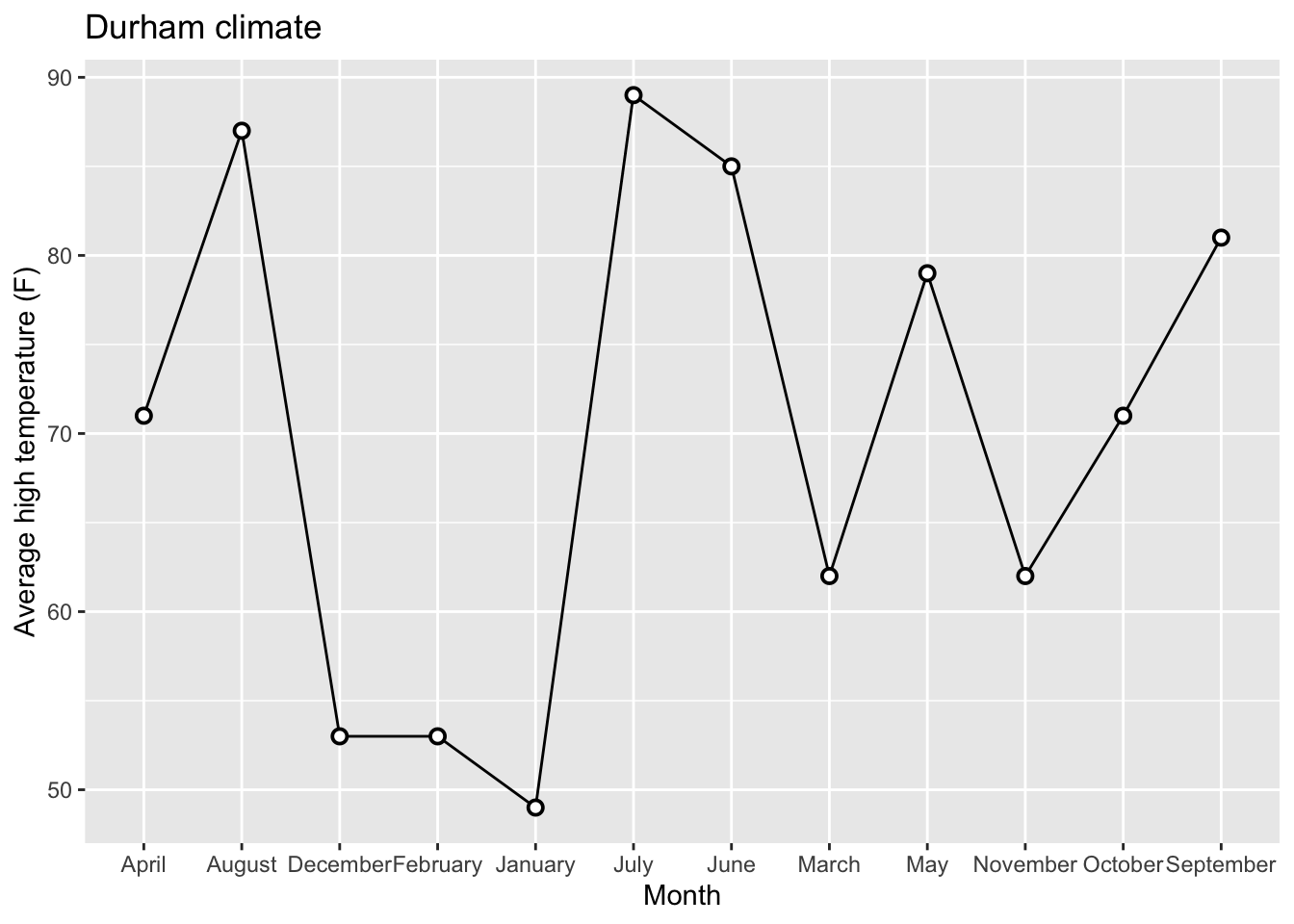
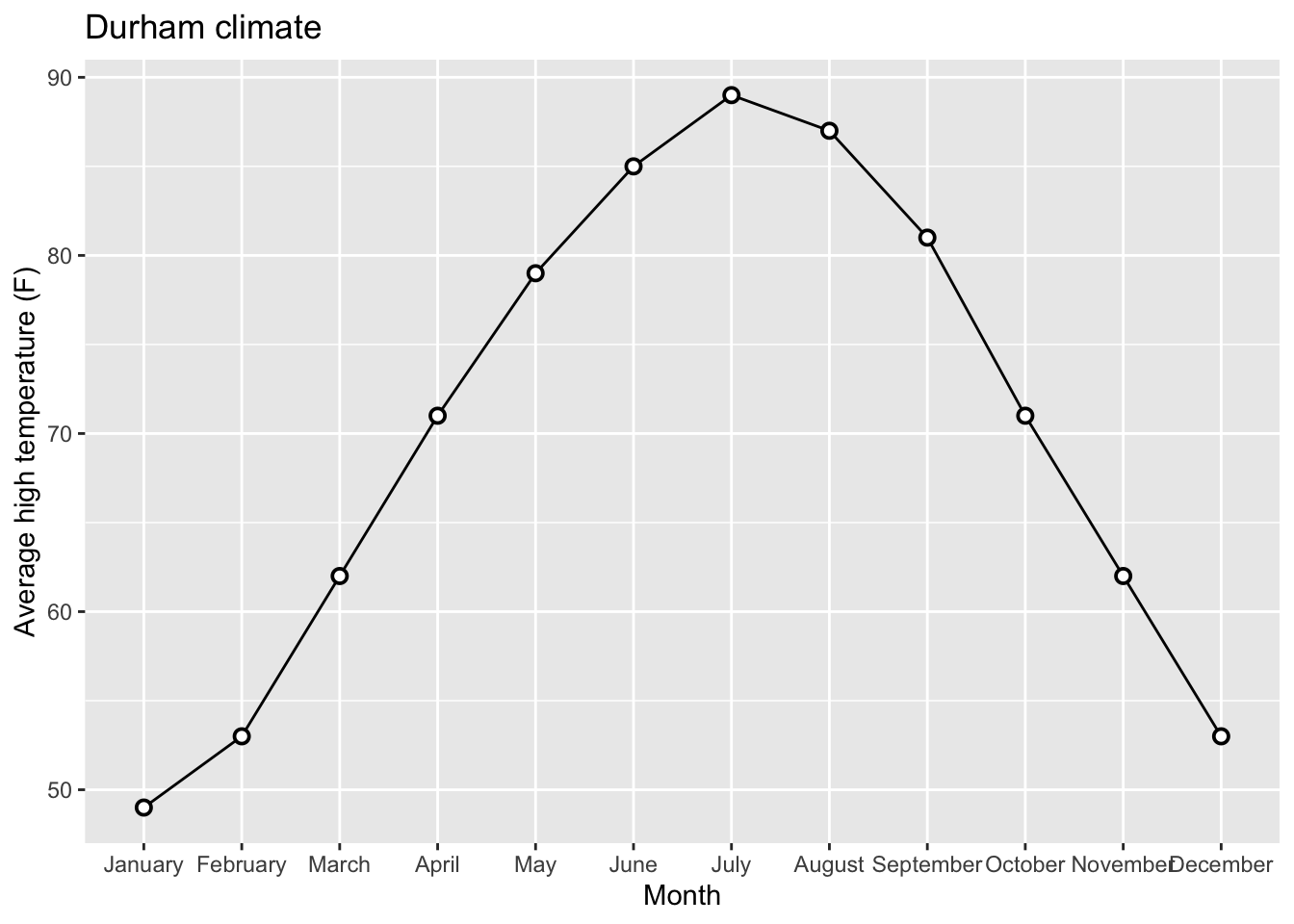
Goal 2: Beautify AE-08 Plot
Original Plot:
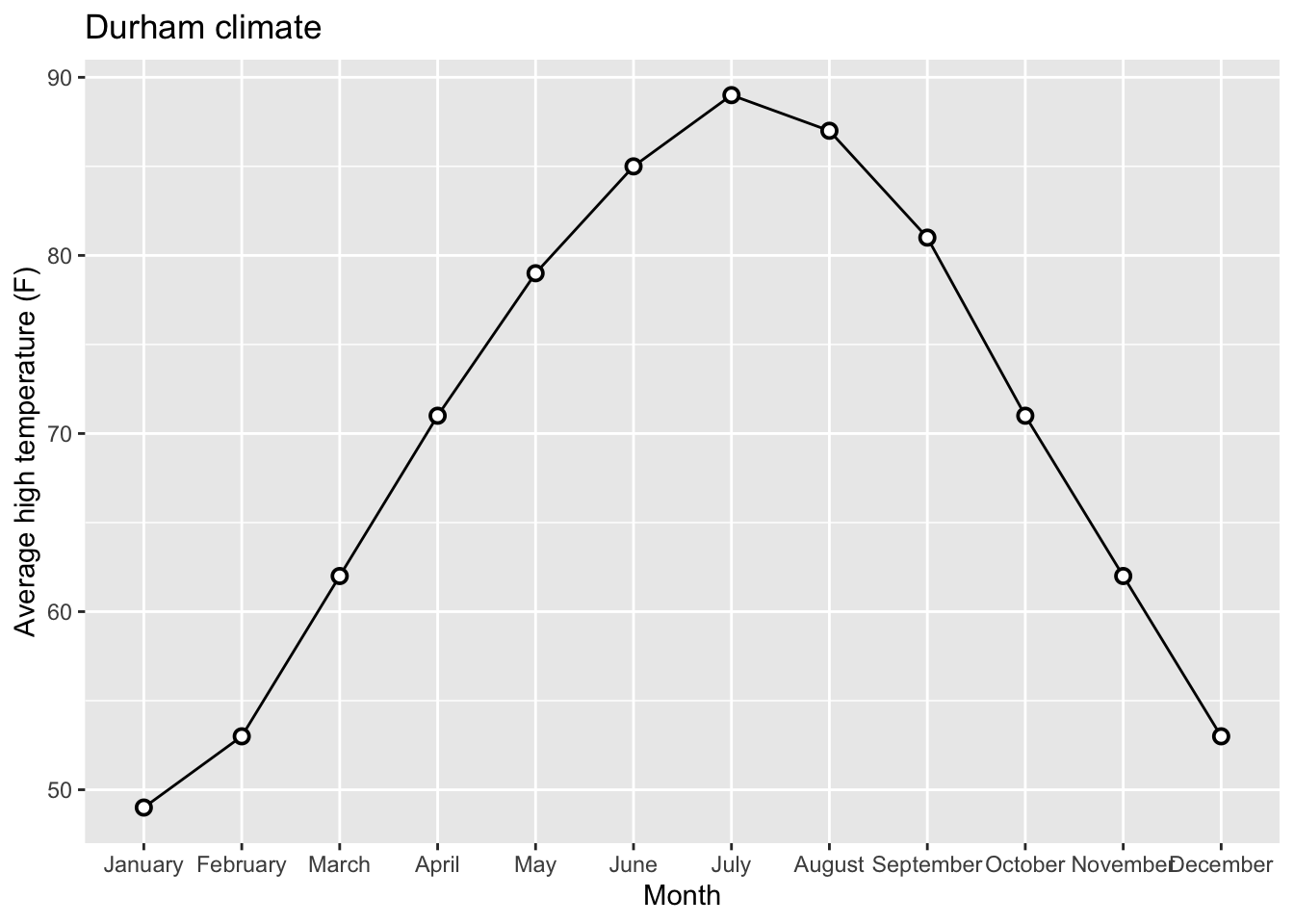
Goal 2: Beautify AE-08 Plot
Releveling Months:
Goal 2: Beautify AE-08 Plot
Goal:
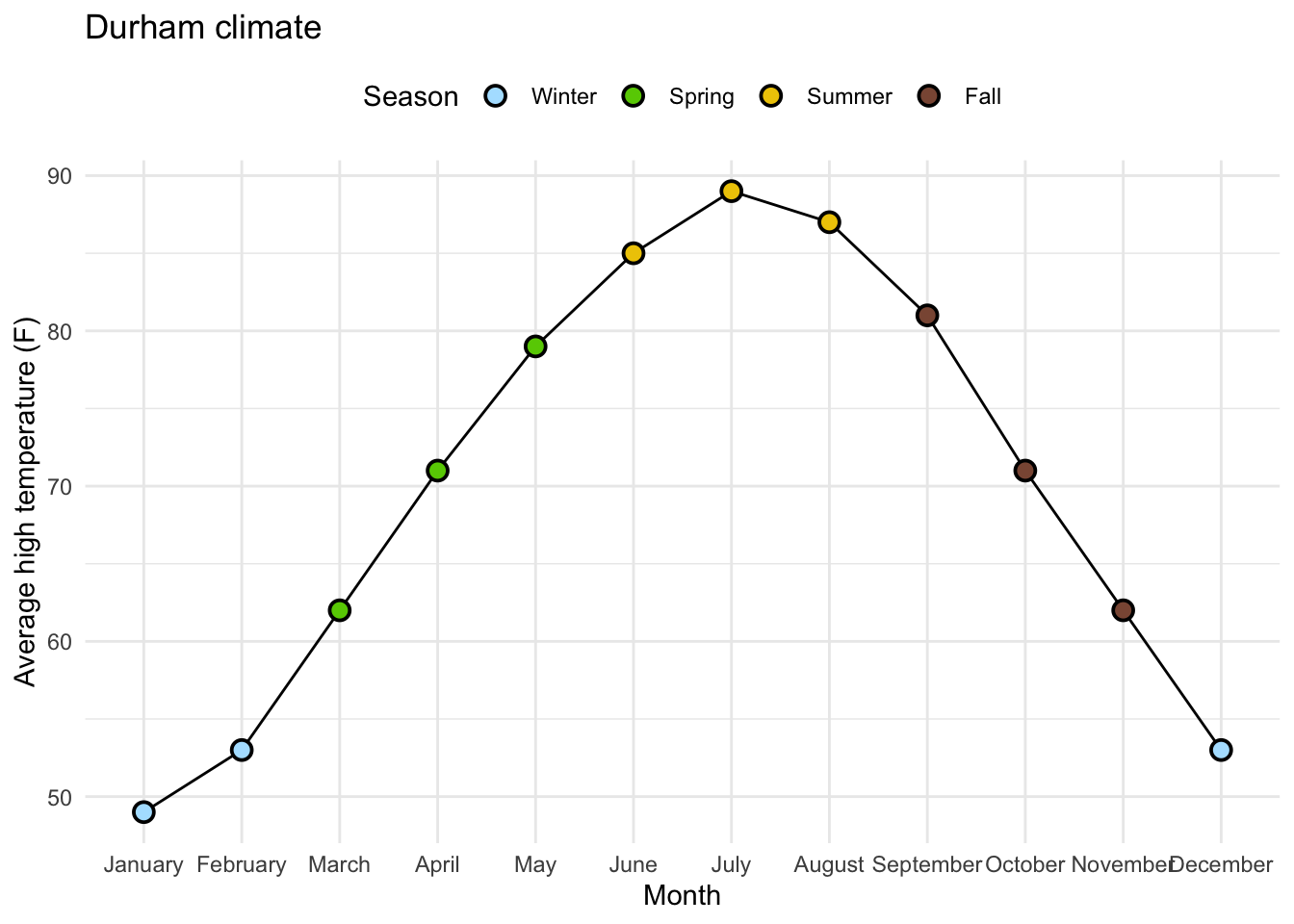
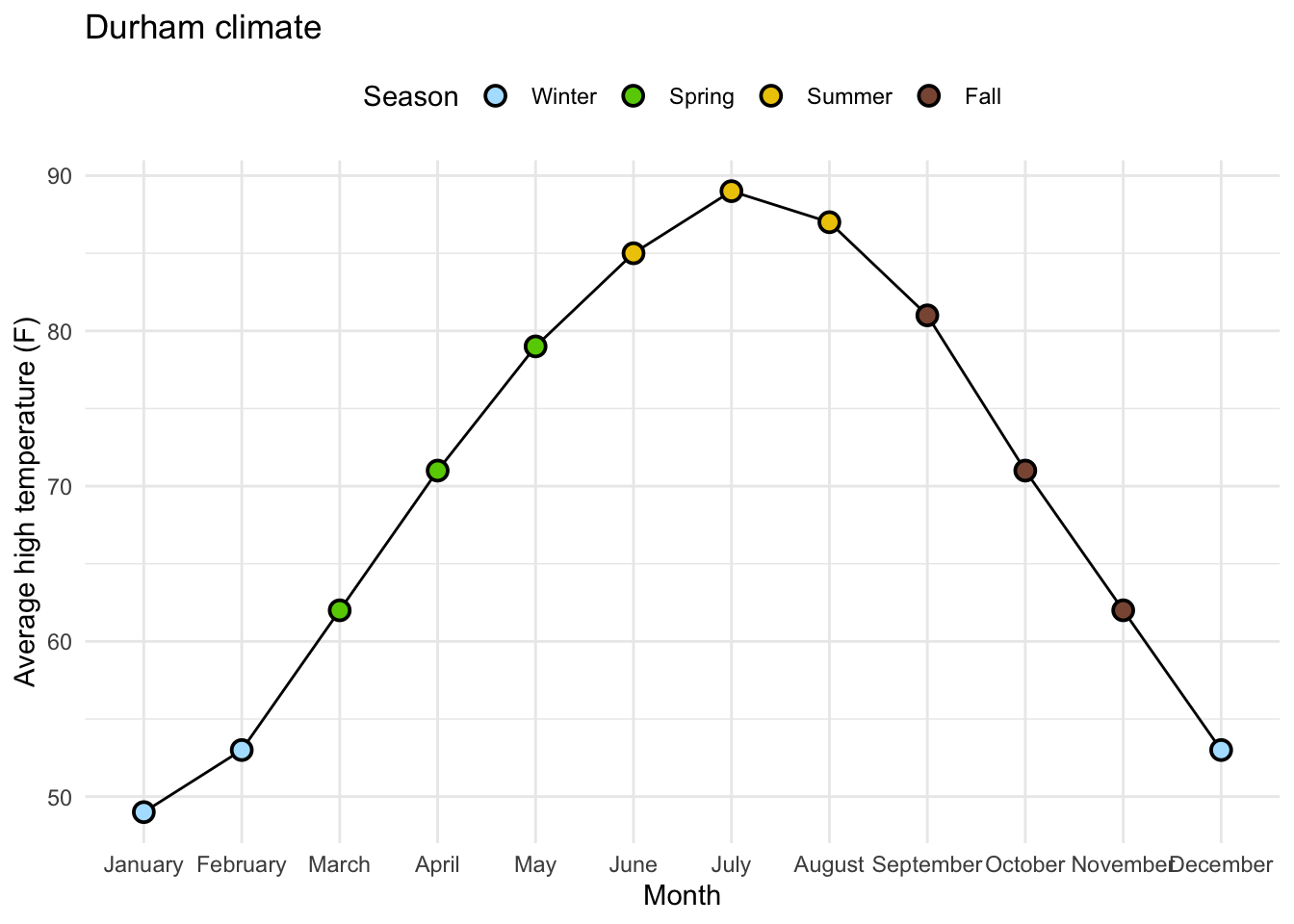
Goal: Beautify AE-08 Plot
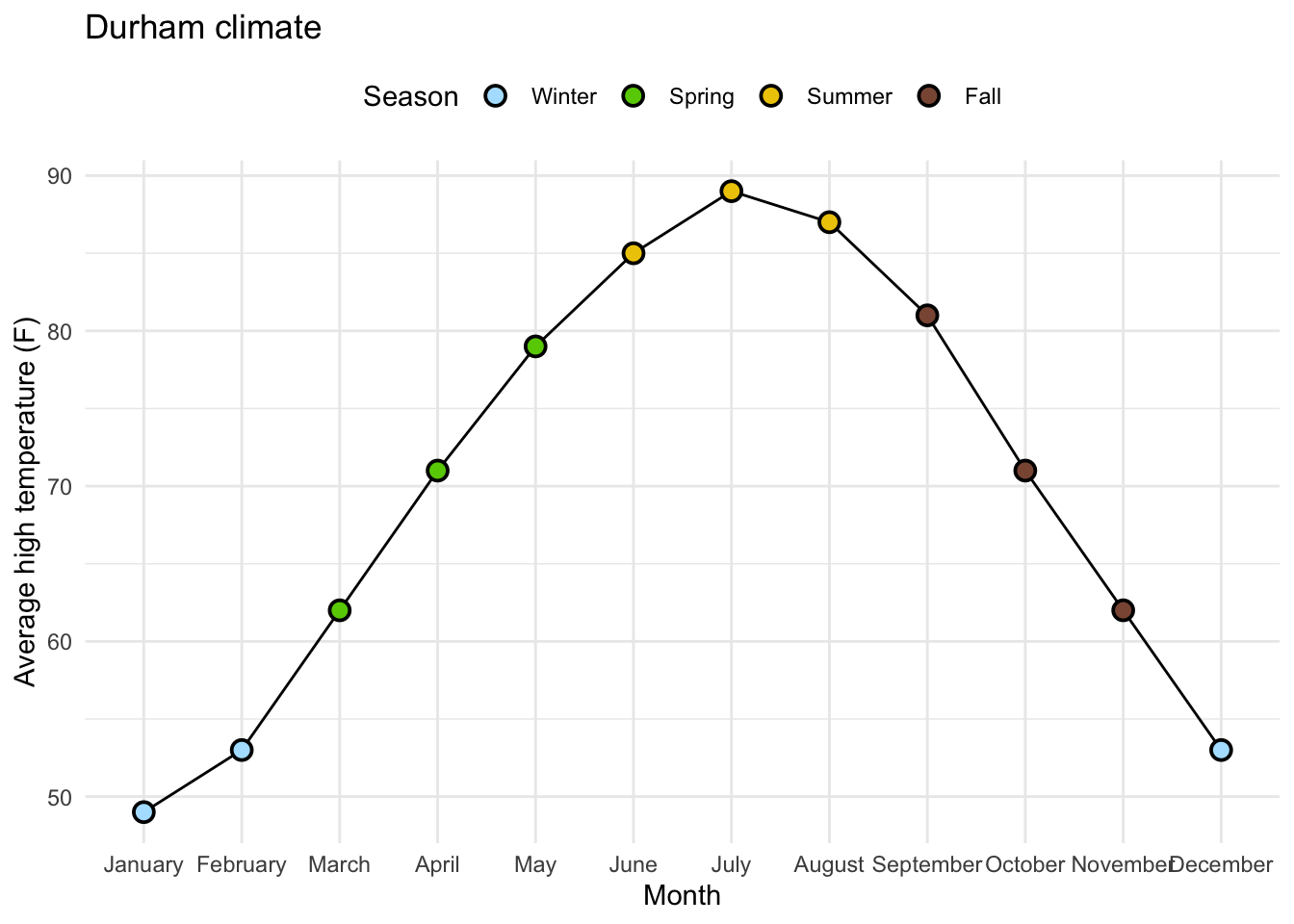
# A tibble: 12 × 4
month avg_high_f avg_low_f precip
<fct> <dbl> <dbl> <dbl>
1 January 49 28 4.45
2 February 53 29 3.7
3 March 62 37 4.69
4 April 71 46 3.43
5 May 79 56 4.61
6 June 85 65 4.02
7 July 89 70 3.94
8 August 87 68 4.37
9 September 81 60 4.37
10 October 71 47 3.7
11 November 62 37 3.39
12 December 53 30 3.43The Code…
Take a look at the printout!W hat does each highlighted portion do?
The Code…
Go ahead and pull today’s AE - mess around with the code.
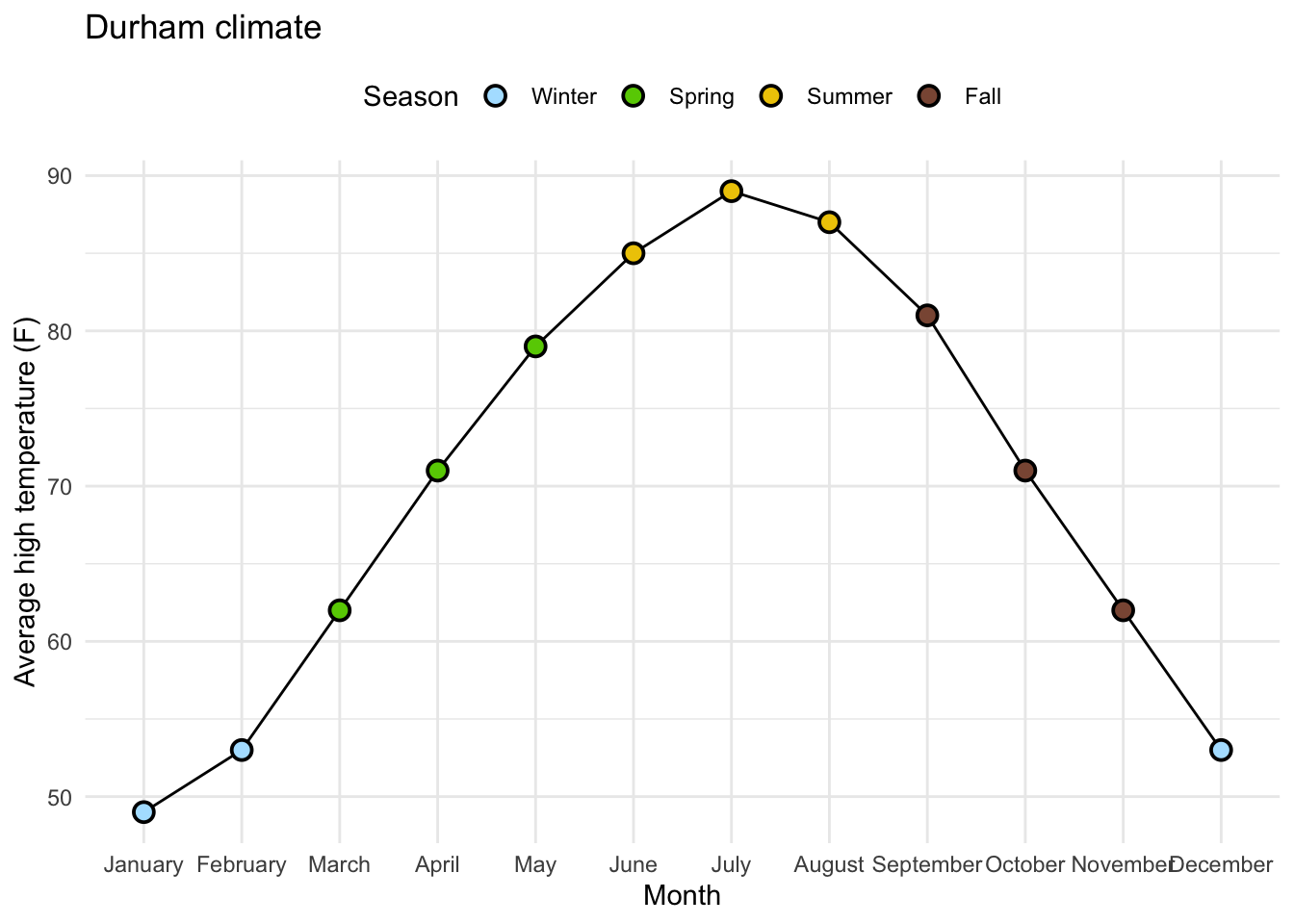
Goal 3: High/Low lines
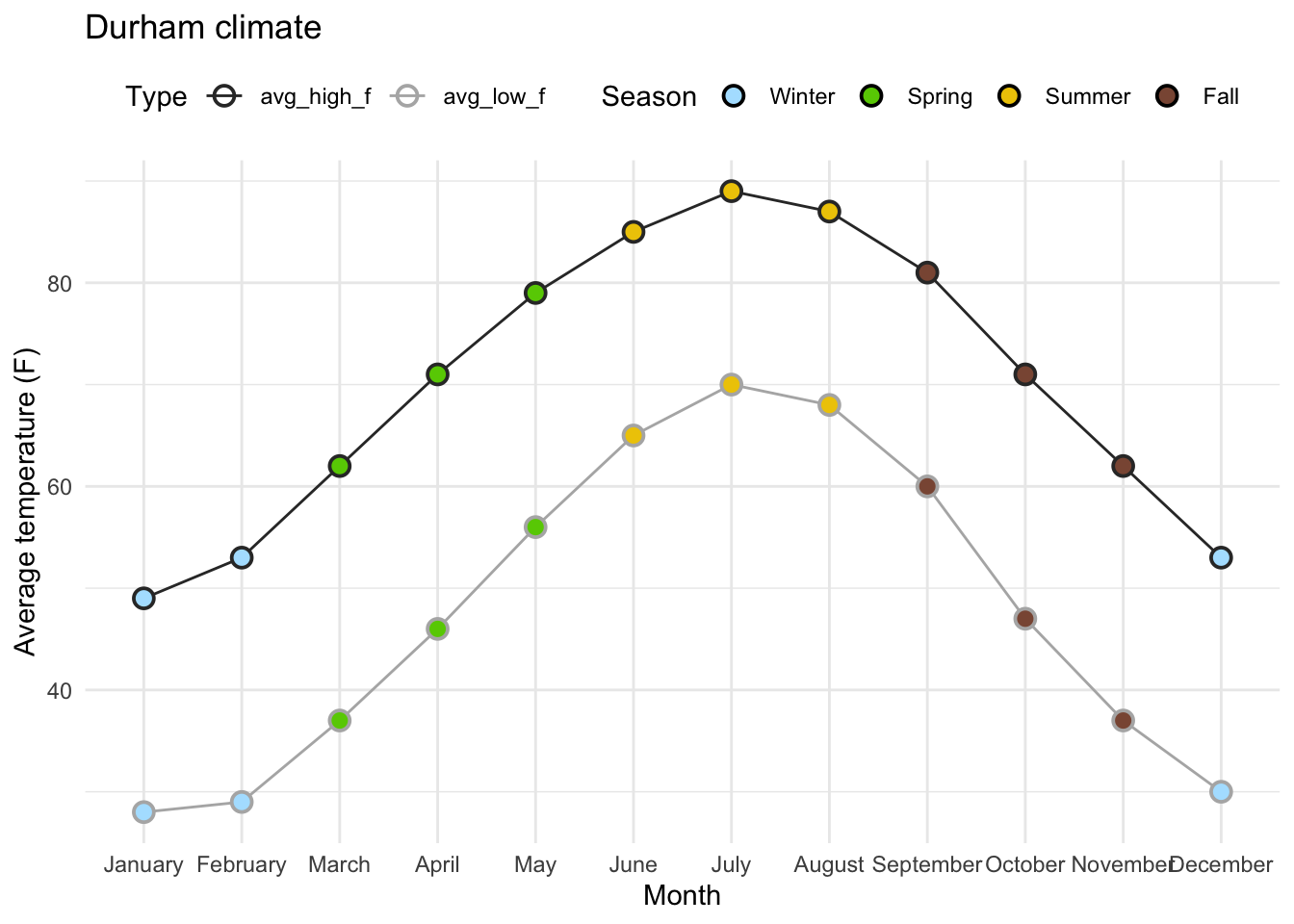
Goal 3: High/Low lines
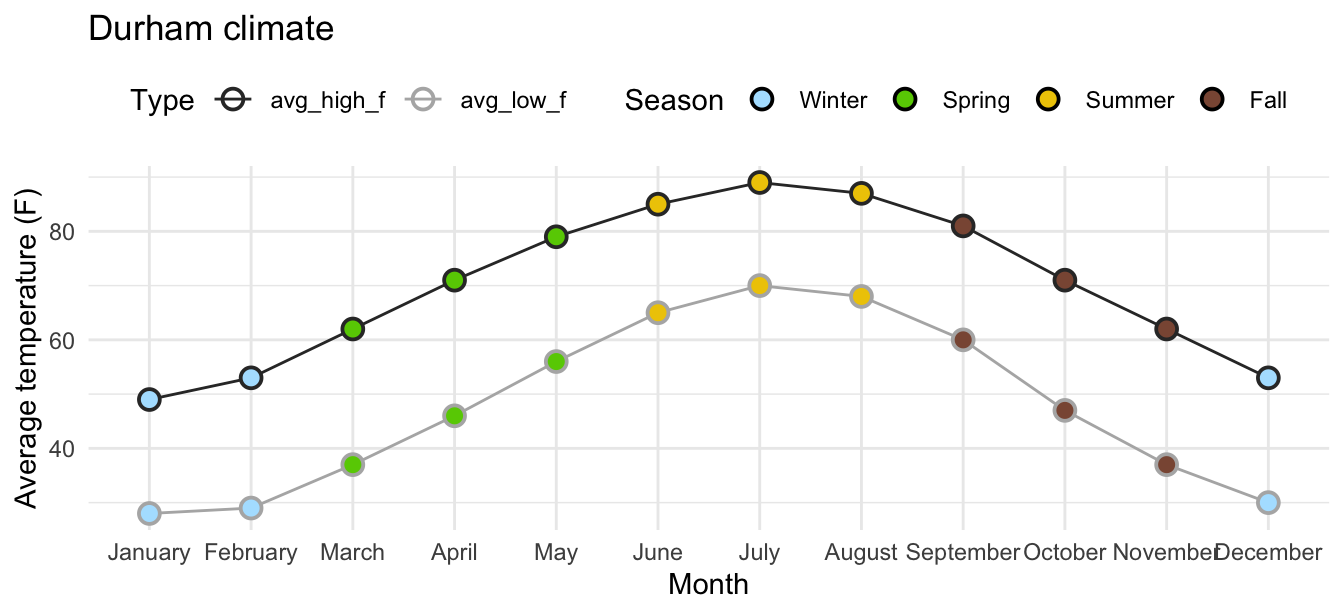
# A tibble: 3 × 5
month avg_high_f avg_low_f precip season
<fct> <dbl> <dbl> <dbl> <fct>
1 January 49 28 4.45 Winter
2 February 53 29 3.7 Winter
3 March 62 37 4.69 Spring